
A PowerPoint Presentation Indexer
(Version 2.2)
| Home | |
 |
Back To Tips Page |
|
|
How it works inside! |
|
A PowerPoint Presentation Indexer(Version 2.2) |
|
One of the constant complaints I get about my two major courses is that there is no index to the presentation. I do not understand why Microsoft has not managed to solve this problem after all these years; apparently providing base functionality is not as important as coming up with new interfaces that don't really add anything to the base functionality of the programs. So I had to solve it on my own.
It took as given that I was not going to try to create a self-contained solution. I don't write in Visual Basic except under duress (the VBA documentation ranks as some of the very worst documentation produced, exceeded in poor quality only by Unix 'man' pages. It is incoherent, disorganized, has no overview, the worst cross-referencing system I've ever seen, and overall it is impossible to learn how to do anything from it. Fortunately, there are some people on the microsoft.public.office.developer.vba newsgroup who were able to show me the core algorithms).
So the result is that I now have a program that can generate an index for every single word in a PowerPoint presentation. The problem is that this is rather useless. since it indexes words like "the", "an", "maybe", "can", "that", "these", and "those", among other useless words. So the question was how to make a program that understood some of the real issues of indexing.
This is a work-in-progress. As I continue working with it, I will add more facilities.
The core components of the system are the following
Normally, we index using "positive indexing". That is, in Word, or FrameMaker, we add special indexing text marks, which are metadata marks. These marks do not appear in the printable rendering but are used by the processor to generate index data. This gives maximum flexibility. In professional systems such as FrameMaker, the index entries themselves can contain markup data to control the font used in the index.
Unfortunately, Microsoft has not really understood their Office product line. Publisher and PowerPoint can't generate indexes. Publisher can't generate page references. There is some delusional system in which they believe that no one could ever need the obvious facilities. However, it is possible to "hijack" the PowerPoint Notes section for this purpose, and I have done so.
So the indexer supports both "positive indexing" and "negative indexing". You choose which one you find most effective. One nice thing about the "negative indexing" is that it can guide you to adding tags in the right places, and that is very convenient.
My style is to spend some time doing "negative indexing", dropping words which are clearly irrelevant, and when I'm finished, I use the words as a guideline to adding the "positive indexing" tags. By using the tool to directly modify the presentation, I can index a 1200-slide presentation with less than a week's effort.
There are problems with using negative indexing. For example, some words start sentences, while others appear in the middle of sentences. In English this means that some words are capitalized while others are not. But some words appear in all-upper-case or all-lower-case, and it would be an error to change them for purposes of indexing (one way to tell an incompetent editor is someone who insists on English rules of capitalization for non-English words, e.g, a section in a book called "Strcpy, Strcat and Strlen". Those words are not English, and must not have bizarre rules applied that change their meaning. A classic example of this is the C++ book by Stroustrup, where English capitalization rules are applied to C++ methods).
An unfortunately side-effect of using negative indexing is that I've had to go back in and reword some slides so they indexing terms, particularly when phrases and permutations are required, are consistent. This has resulted in some redundancy in phrases. For example, I can't write "This and that thing" if I've already indexed the phrase or permutation "This thing"; I had to rewrite it as "This thing and that thing" so the indexing was consistent. But lacking a positive indexing mechanism, it was all I could do. This is why I ultimately figured out how to add positive indexing to the presentation. It was becoming too difficult to do negative indexing.
Some words, which appear in titles, should not be indexed in all-caps, so a title like REPLACING STRING CONTENTS should have index entries such as "Replacing", "String" and "Contents". but a heading such as "strcmp and LC_COLLATE" should not be indexed as "Strcmp" and "Lc_collate". There are user-supplied rules which can ensure that these words get properly indexed.
I have not taken time to create locale-specific rules for some of these situations. The rules below are all hard-coded in the program at this point. Since I only know one other language, I don't feel qualified to extend this program to languages about which I know nothing.
First, I generated a set of heuristics for dealing with text transformations. They will do about 90% or more of all cases, but they don't work everywhere. The simple rules are
To handle the exceptions, a set of rules can be added explicitly by the user, by giving a "pattern" word and a "transformation rule"
These rules override the default case transformation rules.
| Pattern | Effect |
| all lower case | mark as being unchanged, indexed as all lower case |
| exact pattern match | normalize by converting to all lower case and capitalizing the first letter |
| exact pattern match | convert to all-upper-case |
| exact pattern match | convert to all-lower-case |
To handle plurals, I chose to drop them to singular form, and added two rules where the user supplies the pattern word in plural form and the singular form is derived (for verb forms, it is actually the opposite; the plural form is derived from the singular form, because the rules of English verb formation).
| Pattern | Effect |
| plural form ends in s | drop the s |
| plural form ends in es | drop the es |
| plural form ends in ies | replace -ies with -y |
I chose past-to-present-tense transformations by adding two rules
| Pattern | Effect |
| past tense ends in d | drop the d |
| past tense ends in ed | drop the ed |
| gerund form ends in ing | drop the ing |
Note that the singular and plural forms of verbs can be handled by the -s/-es/-ies rules. Note that the gerund form will drop a double-letter at the end of the word, e.g., "dropping" becomes "drop"
| Pattern | Effect |
| 've | word is dropped |
| 'll | |
| 't | |
| 'd | |
| I' | |
| 1-character words | |
| numbers |
My presentations are all about programming. So a "number" has a fairly broad description. It is not just a sequence of digits. An ordinary decimal integer can end in u or U, or l or L. It can also be a floating-point number, a hexadecimal number, and a hex number can have many different representations such as 0x3be, 3beh, 0x3BEL, or even just plain 3BE. Floating point numbers can have an exponential form, and can end in f and integers can end in u or U or l or L. The recognition of a number is hardwired into the program.
The problem with hexadecimal numbers is that they can also spell English words, so I had to provide an "exception" mechanism. Typical exceptions might be the word 'bad' or 'face'. In addition, because of the suffix rules, the Access Control List acronym, ACL, looks like a long hexadecimal constant for the numeric value 172. Indexing function keys, which have names like F1 and F10, would also be impossible unless they could be treated as exceptions. So the rule is that after a hex number is identified, it is compared to a user-supplied list of exceptions, and if it matches the exception, it is treated as a word.
Sometimes what needs to be indexed is not a single word, but a phrase, such as "virtual memory" or "memory descriptor list". These can be indexed in one of two forms: just index the phrase, or index the phrase and permutations of it. For example, it might be desirable to index "virtual memory" as both "virtual memory" and "memory, virtual". To handle this case, the user can supply rules to index phrases or index permutations of phrases. For simplicity, the permutation is limited to 2-word and 3-word phrases.
Sometimes it is desirable to index hyphenated words. User-supplied rules can be supplied to indicate hyphenated word indexing. In the absence of such a rule, the individual words are indexed.
When a rule for certain transformations (such as dropping suffix letters) is provided, and it is typed in all lower case, an automatic rule that matches the capitalized version of the word is generated. This means we typically have to supply only half the rules actually required. So if a rule of the form
texts=*DROP_S
is generated, an automatic rule
Texts=*DROP_S
will also be generated.
This automatic generation also applies to hyphenated phrases.
These rules are often heuristic. The result is an index that may be a bit bulky, and may have some odd capitalizations here and there, but is overall better than having no index. This is the downside of the negative indexing approach. But it infinitely better than having no index at all.
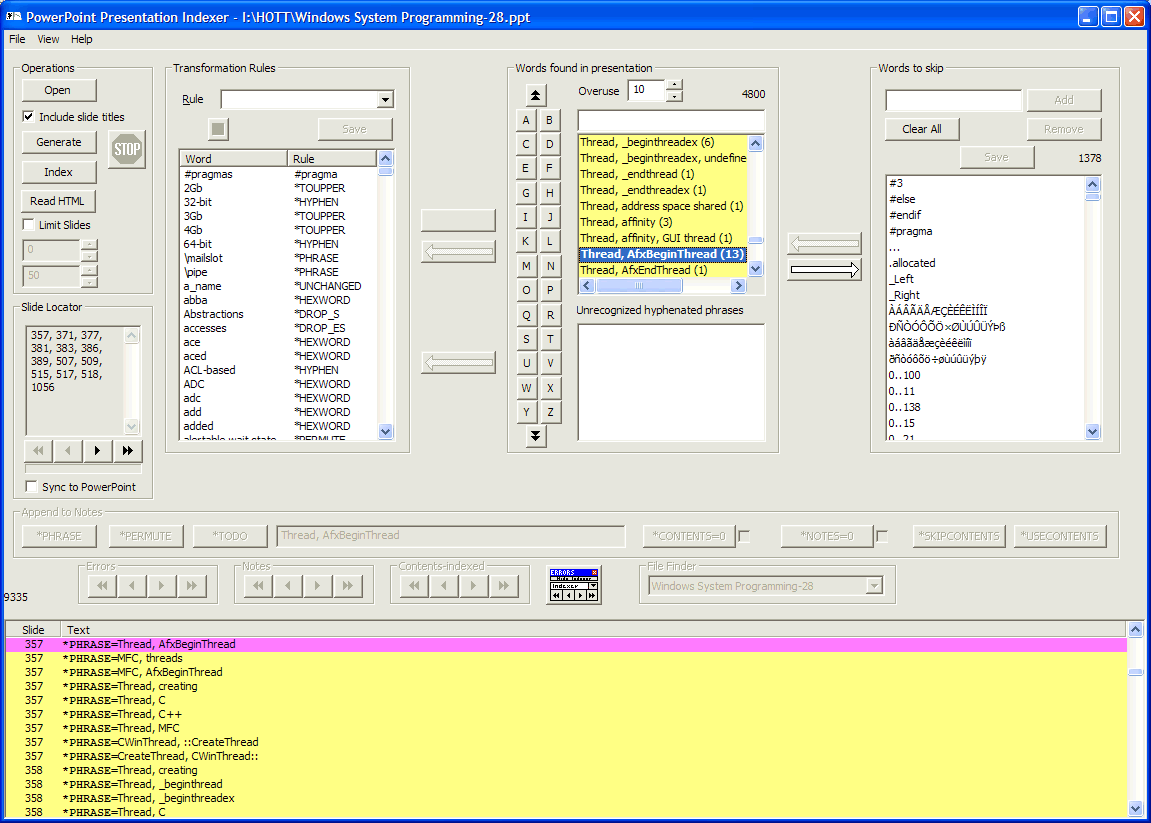
Whenever the program runs, the File menu as an option Open PowerPoint File. This will open the file and read its contents into the program. The text discovered will be displayed in the lower window.
If the PowerPoint file is called Presentation1.ppt, the loading of the index will read in two other files, if they exist. Presentation1.nul is the list of "Null words", the words which will not be indexed. Presentation1.rule will read in a list of transformation rules, such as rules to drop the "s" from a plural word so that there is only one form indexed. If these do not exist, you can created them yourself after creating a list of null words or rules.
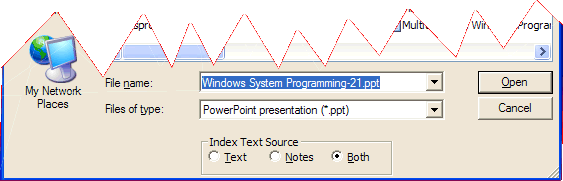
If you use the Open button or the File > Open PowerPoint File... menu item, the File Open dialog, you have the option of selecting the source of indexing text: Text means to use the slide contents; Notes means to look for specific indexing marks in the Notes section, and Both (the default). When a file is opened using the Recent Files menu it is always opened with Both. To exercise specific control, the indexing mode can be turned on or off using Notes rules, and this is the recommended practice.
If you want the slide titles in the table of contents, check the Include Slide Titles option before reading the input file (the TOC is generated during file read). The slide title will appear for any slide that does not have a *HEADINGn= declaration in its notes.
The index will be generated based on the words that are discovered. Click the Index button or use the File > Write Index File menu item to write the index file out. The "index file" is actually three HTML files. The main file is a "frame set" file, which by default is named after the input index file name. So by default, the index file would be called Presentation1.htm. Each of the frames of this file references another file. The left panel is the quick-index key, and will be called Presentation1-ix.htm. The right panel displays the contents, and is called Presentation1-ct.htm. Whatever name is chosen for the main file will be suffixed with -ix and -ct for index and contents.
The bulk of the work is in creating the various rules that will help create a usable index. A skip-word is added by selecting the word in the "Words" list and clicking the ð button to transfer a word from the Words Found list to the Words Skipped list. The ï button will transfer a word back. A transformation rule is created by selecting the desired transform in the Rule box (a dropdown selects the standard rules) and clicking the ï button, at which point a dialog will ask what form of the word should be detected to apply the rule, as described in the Transformations Rules section.
|
|
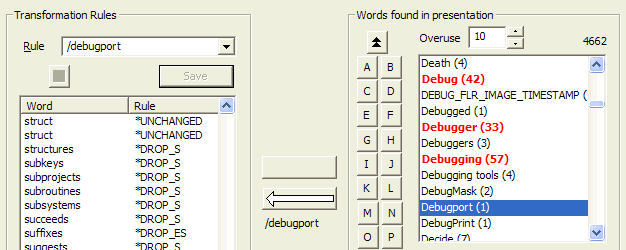
After the Generate is performed, this shows the words and phrases found in the presentation. Words and phrases found as a consequence of elements in the Notes section have a slightly different background.
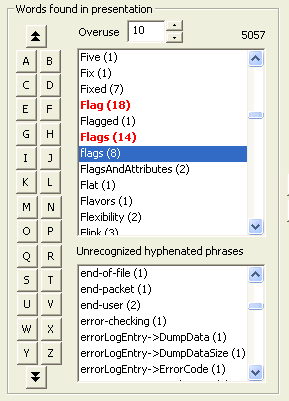
The upper ListBox display shows the set of words that will appear in the index. The (n) value indicates how many instances of the word appear in the index. Note that this represents the number of instances of the word; if the only appearance of the word is where it appears six times on a single slide, it will have a count of (6). However, in the output index the slide number will appear only once. If the word appears "too frequently", it may be useless as an indexing term. The Overuse control sets the number of instances that count as "overuse". In this example, it is set to 10, so the words Flag and Flags are shown in boldface and in a highlight color. This makes it easy to find words that may simply be omitted because they would require more searching than would pay off (for example, in my one course, the word Address appears 262 times!) To expedite the human analysis of the index, the Fast Index buttons,
which include the
The number of items in the list is shown in the top right, in this case, 5057 elements in the list. The lower ListBox shows hyphenated phrases that have been found. This is useful if compound hyphenation phrases will be added by a *HYPHEN transformation rule. Although this picture does not show it, there is now a typein box at the top of this display. This allows you to type in an initial phrase to quickly find it in the list. However, for performance reasons, even if the Sync to PowerPoint option is selected, there is no attempt to synchronize on every keystroke. The presentation will not be synchronized with the selection found by the typein until you move to some other control. When the edit control loses focus, the presentation will be synchronized if the Sync to PowerPoint option has been selected. The most common way this is done is to simply type the Tab key (therefore it is easy to use Shift+Tab to return to the typein window( |
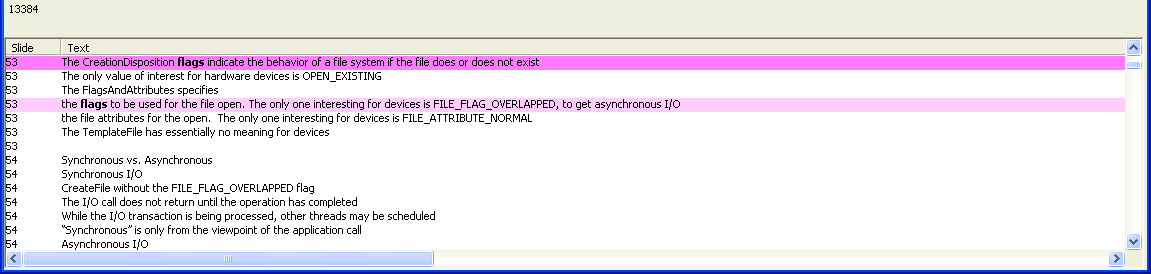
The text of the PowerPoint display is shown at the bottom of the window. The number at the top left indicates how many lines there are in this display. In this case, it is 13384. Note that some lines may be empty, and there are multiple lines for each slide.
When a word is selected in the Words Found In Presentation display, the lines which contain the selected word are highlighted. The currently-selected line is shown in a slightly darker color. The selected word is also shown in boldface.
Double-clicking on a line in the PowerPoint Text Display will bring up the presentation in PowerPoint and position you on the slide. In practice, the Slide column may tell you the slide number is 53, but the actual slide number you see might be different. The reason is that since you started the indexing process you might have inserted or deleted some slides, so the slide number has changed. However, the Indexer actually interfaces to your presentation in terms of the slide ID, an internal number which is unique to each slide. It is assigned when the slide is created and is never reused. So to keep the expected behavior, which is not to go to slide #53, but to go to the slide which contains the text shown, I use the slide ID, which is independent of the slide number. Note that if you drag slides around, they retain their slide IDs, so will be found even if moved within the same presentation.
In a two-monitor system this is highly effective because the PowerPoint Indexer can be on one screen and PowerPoint on another. Here's a sample of the synchronization. In a single-monitor system, the "Floating button box" feature will be more convenient to use; see View > Floating Buttons.
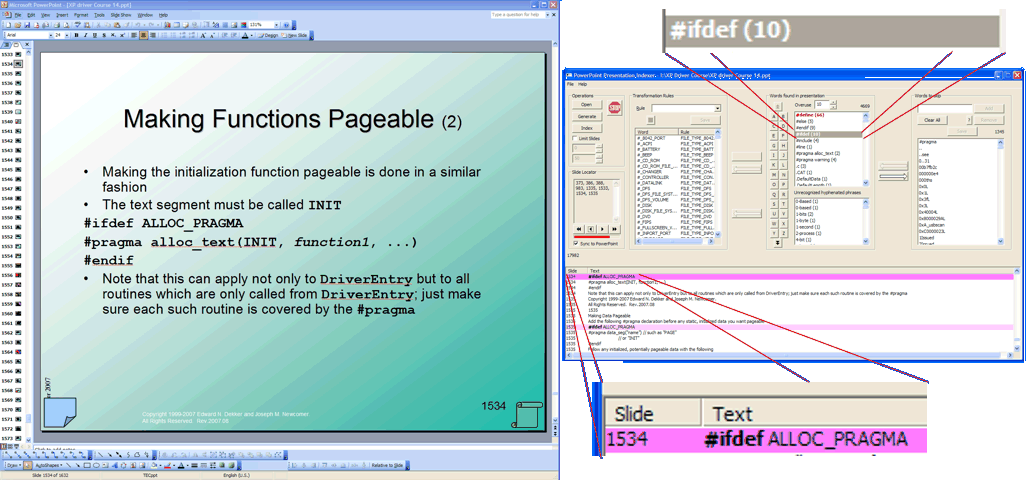
In this example, the user has clicked on the #ifdef (10) line. This creates a list of the 10 instances that appear in the presentation. Then in the lower window, the text lines are all highlighted. The Slide Locator window displays a list of these slides. The buttons below the Slide Locator allow the user to move forward and backward in this list, and the corresponding line in the lower window will be highlighted in a slightly more emphatic color. Double-clicking on the line (which is on slide 1534) will bring up the slide in PowerPoint. In some cases, it is actually convenient to automatically couple the display in PowerPoint to each advance, and this can be done by checking the Sync to PowerPoint check box in the Slide Locator.
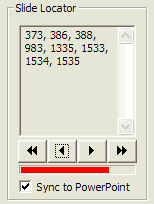
The Slide Locator provides a list of the slide numbers that contain the selected word. These are the slide numbers that would appear in the finished index. In addition, the four buttons at the bottom allow you to scan through
the presentation to find all the instances of the word in the
presentation. The
When the Sync to PowerPoint option is checked, then each time a new slide is selected, the slide will appear in PowerPoint. This saves have to double-click each line in the text display window. A progress bar is shown below the buttons to show the progress through the list of candidate lines.
|
There are four sets of "scan" buttons,
![]() .
These will move to the first slide of interest, previous slide of interest, next
slide of interest, and last slide of interest. Depending on the current
state, any of these buttons, or all of these buttons, might be disabled.
.
These will move to the first slide of interest, previous slide of interest, next
slide of interest, and last slide of interest. Depending on the current
state, any of these buttons, or all of these buttons, might be disabled.
One set is under the Slide Locator window. It is described in the Slide Locator description

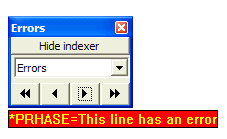
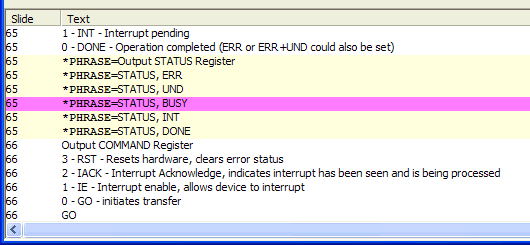
One set is designated Errors. If an error is found while reading the presentation, the line containing will be selected. If the Sync to PowerPoint option is checked, the presentation will be activated and the appropriate slide will be displayed. If you hover the mouse over the line that displays the error, an explanation of the error will pop up:
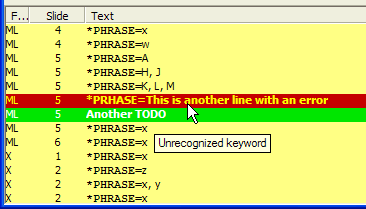
One set is designated Notes. If there is a *TODO= directive in the presentation, this will move from one of these to another.
One is designated Contents-indexed. The philosophy I use is to read in the presentation, drop out all the words I want skipped, and then use the resulting word list as a guideline to what I want to index. What I do is find a slide, put a *SKIPCONTENTS=1 directive into it, and then index the terms I want using *PHRASE=. Ultimately, I will have a *SKIPCONTENTS= in every slide, which is how I know that I've properly indexed the presentation. I needed a way to find the few remaining slides that did not have *SKIPCONTENTS=1 in them. The count of the number of lines that are contents-indexed appears in the list.
In a single-monitor system, it is very inconvenient to have to keep swapping the program and PowerPoint back and forth to scan for slides of interest. To simplify this, a "floating button box" allows for easy perusal of the presentation. This is selected from View > Floating Buttons or by using the Launch Floating Buttons button.
![]()
The floating button box looks like this:
This window is "always on top" and therefore will always be available. Unlike the main display, which has four buttons for each category it supports, this little control has only four buttons and you select the category from the dropdown list. In the case where there is an error or other annotation, the text of the error or annotation is in another little floating window. The position of the text adjusts if the button box is near a window border so the entire string is visible on the monitor that holds the button box, although I made no effort to deal with a button box that itself is split across monitors.
The "Hide Indexer" button stops the indexer main screen from popping up every time a control is activated in the floating button box. This is visually very annoying if the button box is used in a single-monitor system. However, in a dual-monitor system, it is still convenient to use the button box on the primary monitor, but there is no need to hide the indexer application, so I made this an explicit user action to hide it.
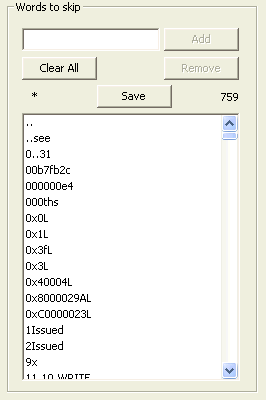
The Words to Skip list contains the list of all character sequences that will not appear in the index. The number on the top right of the control indicates the number of words in the skip list. The * appears at the top left to indicate that the contents of the list have been modified, but have not been saved. They can be saved using the Save button. This will save the contents to the current .nul file. If there is no current .nul file, you will be prompted for a filename. You can also use the File>Save Null Words menu item, which does the same thing as the button, or the File>Save Null Words As... menu item to change the name of the .nul file. Words can be added manually, although this is uncommon, by typing the word into the top left edit control, and clicking the Add button. A word can be removed entirely from the list by selecting the word (or words) to be deleted, and clicking the Remove button. The entire contents of the control can be removed by clicking the Remove All button. Note that saving the file will destroy the contents of the existing file. |
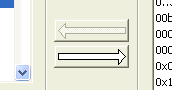 The two arrows between the Words Found list and the Skip Words
list will transfer words back and forth between the two lists. The two arrows between the Words Found list and the Skip Words
list will transfer words back and forth between the two lists.
Because it is so common to want to transfer words to the null-word list, a double-click of a word will do this. You can select more than one term in the null-word list and click the right arrow to transfer them all back across. |
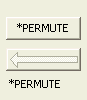 |
When the *PHRASE or *PERMUTE option is
selected in the rules dropdown, the button between the index terms and the
rules is given a caption to indicate which was selected. When the
button is clicked, and a dialog
is popped up that allows you to type the specification of a phrase
to be indexed or a permutation rule to be applied. Note that although it also appears below the arrow button, this is redundant, because the arrow will never be enabled. |
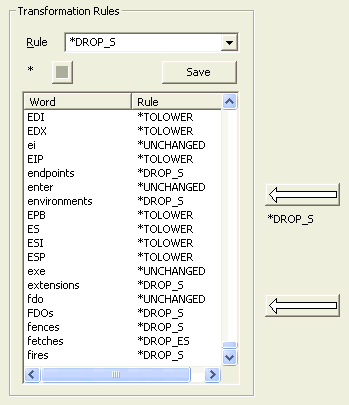 |
This displays the selected words that will have transformations
applied.
The Rule dropdown allows you to select which rule is applied. In addition to the preset rules, a specific replacement rule string can be typed in. The * at the top left corner of the list indicates that the rule list has been modified and has not yet been saved. The rules can be saved by clicking the Save button. Alternatively, the File>Save Rules File menu item will save it as the default file name. If no default file name is given, you will be prompted for a new file name. The File>Save Rules File As... will always prompt for a name. A rules file can be loaded by using the File>Open Rules File menu item. This will delete all the current rules, and replace them with the contents of the file. The upper arrow will use the selected word from the Words Found list to create a rule in the Transformation Rules list. The fule that applies is the rule shown below the arrow (this is a duplication of the word in the Rules box, but is conveniently placed for visibility. The operation will prompt for the desired Word appearance. The lower arrow will use the selected hyphenated phrase from the Hyphenated Words list to create a rule in the Transformation Rules list. The operation will prompt for the desired Word appearance. Rules are added to the end of the list in the order they are created. However, clicking on either of the headers will sort the list by either Word or Rule. The rules file will be written out in whatever order they are currently sorted. Clicking on the column heading will sort the column alphabetically. The Rule column will sub-sort the Word column alphabetically. The small box shown as
Note that there is currently no "undo" capability when rules are deleted. Once they are deleted, they are gone. |
 |
To create a replacement rule, where an
indexed word is replaced by another string entirely, select the desired word
in the word list, then type the desired replacement word into the Rule
window. The text of the rule will appear below the arrow. The
result of this will create a rule of the formdebugport=/debugport These rules are always an exact match basis; there is no automatic capitalized version created. |
It is tedious to have to retype things in the Speaker's Notes section when the computer already has most of the information. The Notes Editor section allows you to easily add new entries to the Notes rules. These entries will always be appended to the Notes section, so you will have to change the order by manual editing of the PowerPoint presentation if the order matters.

Whenever a word or phrase is clicked the the "Words found in presentation" box, it is transferred to the edit control of the Append to Notes area.
For the controls in this area to be enabled, there must at least be a currently-selected slide. See the Sync to PowerPoint option to make this automatic. Otherwise double-click on a line of the text display to select that slide.
The button labeled
![]() will cause a *PHRASE=
entry to be appended to the Notes section of the currently selected slide.
will cause a *PHRASE=
entry to be appended to the Notes section of the currently selected slide.
The button labeled
![]() will cause a *PERMUTE=
entry to be appended to the Notes section of the currently selected slide.
This control is only enabled if there are two or three words in the text box.
will cause a *PERMUTE=
entry to be appended to the Notes section of the currently selected slide.
This control is only enabled if there are two or three words in the text box.
The button labeled
![]() will cause a *CONTENTS=0
entry to be appended to the currently selected slide. The check box to the
right will change the caption to
will cause a *CONTENTS=0
entry to be appended to the currently selected slide. The check box to the
right will change the caption to
![]() and this button will append
a CONTENTS=1 entry to the Notes section of the currently selected slide.
and this button will append
a CONTENTS=1 entry to the Notes section of the currently selected slide.
The button labeled
![]() will cause a *NOTES=0
entry to be appened to the currently selected slide. The check box to the
right will change the caption to
will cause a *NOTES=0
entry to be appened to the currently selected slide. The check box to the
right will change the caption to
![]() and this button will append
a NOTES=1 entry to the Notes section of the currently selected slide.
and this button will append
a NOTES=1 entry to the Notes section of the currently selected slide.
The button labeled
![]() will append a
*SKIPCONTENTS=1 entry to the Notes section of the currently selected slide.
will append a
*SKIPCONTENTS=1 entry to the Notes section of the currently selected slide.
The button labeled
![]() will append a
*USECONTENTS=1 entry to the Notes section of the currently selected slide.
will append a
*USECONTENTS=1 entry to the Notes section of the currently selected slide.
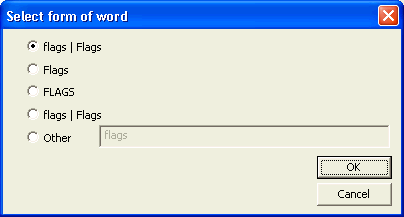 When a transfer is done, a set of canonical representations is
chosen. The selected representation determines the matching rules
applied to the input word to determine if the transformation should take
place. When a transfer is done, a set of canonical representations is
chosen. The selected representation determines the matching rules
applied to the input word to determine if the transformation should take
place.
In accordance with the discussion of case sensitivity of the rules (see below), a word which appears entirely in lowercase will automatically generate a Capitalized replacement rule. This is indicated in this display by showing both rules. Not all transformations allow the creation of a Capitalized rule, and for those transformations, the alternate will not be displayed. The first selection is the word as it appears in the Words Found list. The second selection is the word as it is capitalized. The third selection is the word as it is entirely in uppercase. The fourth selection is the word as it appears entirely in lowercase. If the rule allows an all-lower-case word to have a Capitalized alternate, this is shown. The last entry allows you to specify any other casification or pattern you want. |
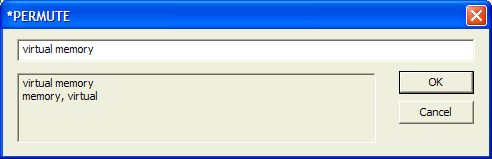 |
When it is desirable to index a permutation, the *PERMUTE
option can be selected, and this enables the button. When the
button is clicked, a dialog box is shown. The phrase to be permuted
can be typed in. The phrase must be typed in as it appears in the document. The lines in the edit control show how it will be indexed. The match is always case-insensitive, and upper-case letters cannot be typed into the control. The OK button will not be enabled until at least two words are typed. It will be disabled if more than three components (hyphenated phrases count as a single "component") are typed in. |
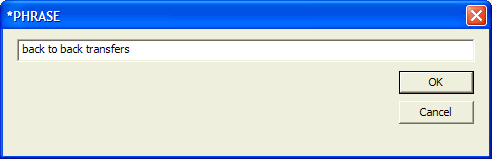 |
When a phrase is to be indexed without permutations, the
*PHRASE option can be selected. The button will bring up the
dialog shown. The phrase to be indexed can be typed in.
The phrase must be typed in as it appears in the document. The match is always case-insensitive, and upper-case letters cannot be typed into the control. The OK button will not be enabled until at least two words are typed. The phrase can contain as many words as needed. |
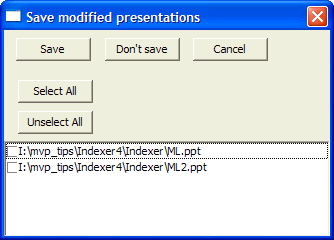 Because it is possible to
have multiple presentations indexed, multiple presentations can be modified.
If a presentation is modified, when an attempt is made to close out the current
indexing task (or exit the program), you will be prompted to save any changed
presentations. Note that if you do not save them here, you will have the
option of saving them from PowerPoint, but that is often less convenient because
PowerPoint will prompt itself.
Because it is possible to
have multiple presentations indexed, multiple presentations can be modified.
If a presentation is modified, when an attempt is made to close out the current
indexing task (or exit the program), you will be prompted to save any changed
presentations. Note that if you do not save them here, you will have the
option of saving them from PowerPoint, but that is often less convenient because
PowerPoint will prompt itself.
The Save modified presentations dialog lists all the presentations that have changed.
The Save button will cause all the selected presentations to be saved. The Don't Save button will not bother to save the presentations but continue the operation that caused this dialog to pop up (such as opening a new indexing task or exiting the application). The Cancel button will cancel the operation, returning you to the point where you started the operation that requested the saving.
To simplify setting or clearing options, the Select All and Unselect All buttons will check or uncheck all the names that appear in the list box.
The dialog can be resized to show longer names or more names.
Note: there seems to be some strangeness about the PowerPoint automation interface; it erroneously returns TRUE to indicate that a presentation has changed even though the presentation has already been saved explicitly in PowerPoint. I have no idea why it does this, so sometimes this prompt is spurious.
The rules that I've created are directed towards English-language presentations. However, the set is extensible, and for any language for which there can be a consistent set of transformations from past to present forms or plural to singular forms, the set can be easily extended.
The rules file is a text file, whose syntax is as shown in the Example rule column.
The rules are normally case-sensitive, and are applied when a word is found. In the absence of a transformation rule, the hardwired transformation rules discussed below are applied. However, to limit the number of rules typed for common cases, the *DROP rules have a specific generalization: if the first letter is lowercase and there are no uppercase letters in the string, an alternative form with an uppercase letter is generated. This handles the situation in many languages similar to English where the first word of a sentence is capitalized. It would not be necessary for a language like German where nouns are uniformly capitalized.
| Rule | Example rule | input | result | notes |
| *DROP_D | iced=*DROP_D | iced Iced |
ice Ice |
If the first character is a lower-case letter, and there are no other uppercase letters in the word, a secondary rule is created that has the first letter uppercased. |
| Iced=*DROP_D | iced Ice |
iced Ice |
If the first character is an upper-case latter, no additional rule is generated. | |
| *DROP_ES | suffix=*DROP_ES | suffixes Suffixes |
suffix Suffix |
If the first character is a lower-case letter, and there are no other uppercase letters in the word, a secondary rule is created that has the first letter uppercased. |
| Suffix=*DROP_ES | suffixes Suffixes |
suffixes Suffix |
If the first character is an upper-case latter, no additional rule is generated. | *DROP_ED | worked=*DROP_ED | worked Worked |
worked Work |
If the first character is a lower-case letter, and there are no other uppercase letters in the word, a secondary rule is created that has the first letter uppercased. |
| Worked=*DROP_ED | worked Worked |
worked Work |
If the first character is an upper-case letter, no additional rule is generated. | |
| *DROP_ING | working=*DROP_ING | working Working |
work Work |
If the first character is a lower-case letter, and there are no other uppercase letters in the word, a secondary rule is created that has the first letter uppercased |
| dropping=*DROP_ING | dropping Dropping |
drop Drop |
If the result of applying this rule is to create a word whose two last letters are the same, the duplicate letter is dropped. | |
| Working=*DROP_ING | working Working |
working Work |
If the first character is an upper-case letter, no additional rule is generated | |
| *DROP_LY | normally=*DROP_LY | normally Normally |
normal Normal |
If the result of applying this rule is to create a word whose two last letters are the same, the duplicate letter is dropped. |
| Normally=*DROP_LY | normally Normally |
normally Normal |
If the first character is an upper-case letter, no additional rule is generated | |
| *DROP_S | thing=*DROP_S | things Things |
thing Thing |
If the first character is a lower-case letter, and there are no other uppercase letters in the word, a secondary rule is created that has the first letter uppercased. |
| Thing=*DROP_S | things Things |
things Thing |
If the first character is an upper-case latter, no additional rule is generated. | |
| *HEXWORD | add=*HEXWORD | add Add ADD |
add Add (word is dropped) |
Allows the word, which might be misinterpreted as a hex value, to be considered as a word. Note that if the pattern is all lowercase, it applies to both lowercase and capitalized versions. To get the all-upper-case version, an all-upper-case rule must also be added. |
| Add=*HEXWORD | add Add ADD |
(word is dropped) Add (word is dropped) |
If the pattern is capitalized, only the capitalized version will be recognized. To get the all-upper-case version, an all-upper-case rule must also be added. | |
| ADD=*HEXWORD | add Add ADD |
(word is dropped) (word is dropped) ADD |
This form of rule only allows an all-upper-case version to be recognized. To get both capitalized and all-lower-case recognized, an all-lower-case rule must be added. To get capitalized-only to be recognized, a capitalized rule must be added. | |
| *HYPHEN | common–things=*HYPHEN | common-things Common-things |
Common-things Common-things |
Does not treat hyphen as a delimiter
between two words, but treats the hyphenated phrase as if it were a single
word. If the first character is a lower-case letter, and there are
no other uppercase letters in the hyphenated phrases, a secondary rule is
created that has the first letter uppercased. Note that individual words of a hyphenated phrase are not indexed independently. |
| Common–things=*HYPHEN | common-things Common-things |
common things Common-things |
If the first letter is upper-case, the rule only matches exactly; the first case, which is not an exact match, is now treated as two separate words | |
| *IES_TO_Y | tries=*IES_TO_Y | tries Tries |
try Try |
If the first character is a lower-case letter, and there are no other uppercase letters in the word, a secondary rule is created that has the first letter uppercased |
| Tries=*IES_TO_Y | tries Tries |
tries Try |
If the first character is an upper-case letter, no additional rule is generated | |
| *NORMAL | cat=*NORMAL | cat | Cat | Note this is indistinguishable from the default behavior; it is more interesting in other cases |
| caT, cAt, cAT, Cat, CaT, CAt, CAT | caT, cAt, cAT, Cat, CaT, CAt, CAT | The match must be exact. | ||
| cAt=*NORMAL | cAt | Cat | This handles some weird cases that arise from programming. | |
| cat, caT, cAT, Cat, CaT, CAt, CAT | cat, caT, cAT, Cat, CaT, CAt, CAT | |||
| CAT=*NORMAL | CAT | Cat | Particularly useful for converting all-caps letters in titles and section headings to indexable entities. | |
| *PERMUTE | memory allocation=*PERMUTE | memory allocation Memory allocation Memory Allocation MEMORY ALLOCATION |
Memory allocation Allocation, memory |
Rule must be all lower-case, but does a case-independent match. Allows multiword phrases to be recognized and indexed under multiple permutations. Note that only two-word and three-word permutations are currently supported.
Note that all words in the permutation will still be individually indexed, unless they are added to the null-word list. Permutations may also be supplied in Notes Rules. |
| finite state machine=*PERMUTE | finite state machine Finite state machine FINITE STATE MACHINE |
Finite state machine State machine, finite Machine, finite state |
||
| *PHRASE | memory allocation=*PHRASE | memory allocation Memory allocation Memory Allocation MEMORY ALLOCATION |
Memory allocation | Rule must be all lower-case, but does a case-independent match. Allows multiword phrases to be recognized and indexed.
Note that all words in the phrase will still be individually indexed, unless they are added to the null-word list Phrases may also be supplied in Notes Rules. |
| *TOUPPER | cat=*TOUPPER | cat | CAT | An exact match is required |
| caT, cAt, cAT, Cat, CaT, CAt, CAT | caT, cAt, cAT, Cat, CaT, CAt, CAT | Strings which are not exact matches are ignored | ||
| cAt=*TOUPPER | cAt | CAT | ||
| cat, caT, cAt, Cat, CaT, CAt, CAT | cat, caT, cAt, Cat, CaT, CAt, CAT | |||
| *TOLOWER | CAT=*TOLOWER | CAT | cat | |
| cat, caT, cAt, cAT, Cat, CaT, CAt | cat, caT, cAt, cAT, Cat, CaT, CAt | |||
| cAt=*TOLOWER | cAt | cat | ||
| cat, caT, cAT, Cat, CaT, CAt, CAT | cat, caT, cAT, Cat, CaT, CAt, CAT | |||
| *UNCHANGED | strcpy=*UNCHANGED | strcpy | strpcy | Requires exact match; the text is unchanged |
| replacement rule | running=run | running Running |
run Running |
Requires an exact match |
| Running=run | running Running |
running run |
Note that the replacement is exact, there is no case change in the replacement | |
| Running=Run | running Running |
running Run |
||
| default behavior | this is what happens if no rule is found. This behavior is hard-wired into the program. | anything Anything |
Anything Anything |
A word which is not otherwise handled will have its first letter uppercased, providing all the remaining symbols are lower-case letters |
| anyThing | anyThing | Unchanged, has uppercase letter within it | ||
| word322 | word322 | Unchanged, has digits within it | ||
| some_program_name | some_program_name | Unchanged, has non-letter within it | ||
| www.flounder.com | www.flounder.com | Unchanged, has non-letter within it | ||
| ’s | file's 1980’s |
file 1980 |
English possessive rule, and in odd cases, an English plural rule (formally, non-words which are plural should have ’s, for example, LPT’s is the official plural of LPT, although I think this convention is silly and I ignore it) | |
| 've 'd 't |
I've Should've can't |
not indexed |
Note that if for some reason it was desirable to get the effect that things=>thing but Things should not be transformed, the the *DROP_S rule would not work, but an exact replacement rule things=thing, would accomplish the task.
| ^K ('\x0B', chr$(11)) | Converted to a space. This is the shift-return character in multiline entries. | |
| character drops | The following characters are ignored, and are treated as if they are whitespace. Their presence in a word splits the word into two pieces. Note that this prevents the use of hyphenated words such as pre-computed, all-encompassing, and so on | |
| ~ ! $ % ^ & * ( ) + = [ ] { } | ; " ' < > ? , . … “ ” ‘ ’ | ||
| character trims | The following characters will be trimmed from the beginning or end of words | |
| . space ... | ||
| The following characters will be trimmed from the end of words | ||
| space | ||
At this point, the resulting word is tested to see if it starts with "http:" "https:", "d:" for any lowercase or uppercase letter d, or "www.". If it does, it is treated as a single word. Note that this does not permit ( or ) inside a URL, but only profoundly antisocial Web sites use those. If it is not a URL, the following rules are applied
| Example phrase | Effect |
| http://here/there.htm | phrase is unchanged |
| me@company-name.com | phrase is unchanged |
| https://secure.pages/secret.htm | phrase is unchanged |
| m:\filepath\name.ext | phrase is unchanged |
| \\name\dev | phrase is unchanged |
If the integrity rules were not applied, the following rules are applied:
| Rule | Example/effect | |
| character drops | The following characters are ignored and treated as if they are whitespace | |
| : / - \x96 \x97 \\ | ||
| \x96 is an en-dash, and \x97 is an m-dash | ||
| string length | < 2 | Single-character results are not indexed |
The drop rules are applied after the above canonicalization. This is important because otherwise there would be the need to create drop rules for singular and plural forms, various tenses, and so on.
The goal here was to deal with PowerPoint presentations of programs. So the drop rules are somewhat ad hoc for this purpose.
| Rule | Example | Interpretation |
| numbers | 123 123L 123l 123. 0.0 .123 123E+14 -123e-12 |
A sequence of digits, a decimal number, a
floating number, are all rejected. A decimal number that ends in
lower-case or upper-case L is considered to be a number. (currently, U/u suffixes are not supported) |
| hex numbers | 0x | Any string starting with 0x or 0X is not indexed |
| bc07 | A string that looks like a hex number is not indexed (see note) | |
| bc07L | A hex number that ends with an upper-case or lower-case L. | |
| 0h | A sequence of hex digits ending in h is not indexed | |
| English words or computer terms that might be misinterpreted as hex numbers will be dropped, unless there is a *HEXWORD exception to them. This include words like "cafe", "face", "add", and "ACL". The latter may come as a surprise, but it is the hex value AC followed by the Long constant indicator. | ||
| ’t (suffix) | hadn't | Handles English contractions can't, won't, shouldn't, and so on |
| ’ve (suffix) | could've | Handles English contractions should've, could've, and so on |
| I’ (prefix) | I'm | Handles English contractions on I, such as I'm, I'd, I'll |
While for purposes of rules, rules are treated as case-sensitive, this has problems in producing an alphabetical index, because the index would be sorted as A..Za..z, meaning "thing" comes out in an entirely different place than "Thing". This is counterintuitive insofar as user expectations. So the index-sorting algorithm is case-independent.
If the word starts with a number (that is, it is not just a number, which is a rule that results in a drop), then it is sorted in its integer position, and the suffix is sorted alphabetically. Thus the sequence that would sort alphabetically as
100MB
10ms
1GB
1ms
20KHz
2GB
33rpm
4.7MHz
will actually sort in increasing numerical order, as
1GB
1ms
2GB
4.7MHz
10ms
20KHz
33rpm
100MB
These rules appear in the Slide Notes of a slide. They may appear with other lines; if you are using the notes, you can put these at the end. The actual notes contents are ignored, unless a line starts with a * and has one of the keywords shown in the table, followed by an equal sign. There cannot be any spaces between the * and the keyword and the keyword and the =.
By using this, you can put these indexing marks after your Speaker Notes, if you use them, and therefore they will not interfere with your use of notes. By requiring the use of the * as the first character in the line (it must not be preceded by a space or any other character), it is unlikely that your notes will "accidentally" contain something that looks like one of these directives.
Note the default values are established at the time when the presentation is opened using the settings *CONTENTS=1 and *NOTES=1, unless you override the setting explicitly in the File Open dialog.
| Keyword | Example | Appears in index as | Notes |
| *ALIAS=name | *ALIAS=book | [book] 1, 2, 7-9 | Reports the current file as the specified alias in the index |
| *CONTENTS=0|1 | *CONTENTS=0 | Turns off content indexing for the current slide and all subsequent slides | |
| *CONTENTS=1 | Turns on contents indexing for the current slide and all subsequent slides | ||
| *HEADING1=text | *HEADING1=Introduction | Table of contents 1st-level entry | These will be processed even if *USECONTENTS=0 |
| *HEADING2=text | *HEADING2=Detail | Table of contents 2nd-level entry | |
| *HEADING3=text | *HEADING3=Subdetail | Table of contents 3rd-level entry | |
| *INCLUDE=filename | *INCLUDE=something.ppt | [something] 1, 2, 7-9 | Indexes the specified file |
| *INCLUDE=filename>alias | *INCLUDE=c:\presentations\something.ppt>main | [main] 1, 2, 7-9 | Uses the alias name for display of the index information |
| *NOTES=0|1 | *NOTES=0 | Turns off notes processing starting at this
point in the notes and for all subsequent slides This does not affect *TODO, *HEADING1 and *HEADING2 elements |
|
| *NOTES=1 | Turns on notes processing starting at this point in the notes and for all subsequent slides | ||
| *PHRASE=term | *PHRASE=Any old phrase | Any old phrase | The term is indexed exactly as shown; there is no case transformation. This is similar to the *PHRASE rule. |
| *PHRASE=Thing, Large | Thing Large |
Any phrase separated by commas indicates a multilevel index item | |
| *PHRASE=Cat,, Little Gray, nice | Cat, Little Gray nice |
A double comma causes the comma to be treated as an ordinary character, not as a level separator | |
| *PERMUTE=phrase | *PERMUTE=Conditional compilation | Compilation conditional Conditional compilation |
The terms are normalized according to the rules
of permutation. Note that case normalization rules apply as for the
*PERMUTE keyword. As with the *PERMUTE rule, only two-word and three-word phrases are handled; permutations will be case-transformed according to the same rules use for the *PERMUTE rule. |
| *SKIPCONTENTS=0|1 | *SKIPCONTENTS=1 | Does not index the contents of this slide only. Upon the completion of the slide, the contents flag is reset to the value decided by the most recent *CONTENTS= or set by the File Open dialog, whatever is prevailing. | |
| *SKIPCONTENTS=0 | Accepted but has no meaning | ||
| *TODO=text | *TODO=Check consistency of 'Threads' | Note added to display | This will be processed even if *USENOTES=0 |
| *USECONTENTS=0|1 | *USECONTENTS=1 | Forces indexing the contents of this slide only. Upon completion of the slide, the contents flag is reset to the value decided by the most recent *CONTENTS= or set by the File Open dialog, whatever is prevailing. | |
| *USECONTENTS=0 | Accepted but has no meaning |
These rules can be added directly from the Indexer by the Append to Notes controls in the Notes Editor section.
When a line is displayed in the table that was added by a Notes Rule, it is highlighted in a different color.
When multiple PowerPoint presentations exist, it is nice to be able to index all of them together. This allows for multiple presentations to be indexed with a single index, and also encourages uniform indexing across presentations even if they are indexed separately.
I thought of several approaches to this, but finally settled on the notion of using a directive, *INCLUDE=filename, which would appear in the Notes section. This means that to index a collection of presentations, it may be necessary to create a "master" PowerPoint presentation which has exactly one slide, which contains a set of *INCLUDE directives to the other presentations.
An attempt to create a circular *INCLUDE dependency will be detected, and the *INCLUDE that would result in circular inclusion will be ignored. It will be flagged as an error line.
A filename may be specified as an absolute path, a relative path, or with no path.
| Path type | Example | File name actually used |
| Absolute path name | c:\path\whatever.ppt | c:\path\whatever.ppt |
| \path\whatever.ppt | \path\whatever.ppt | |
| \\servername\sharename\path\whatever.ppt | \\servername\sharename\path\whatever.ppt | |
| Relative path name | ..\whatever.ppt | A name based on the directory in
which the master presentation is found; if we started in
c:\mypresentations\somevent\master.ppt then the resulting path would be c:\\mypresentations\someevent\..\whatever.ppt If, for some reason, the path of the master presentation is empty, the current working directory is substituted. |
| Plain file name | whatever.ppt |
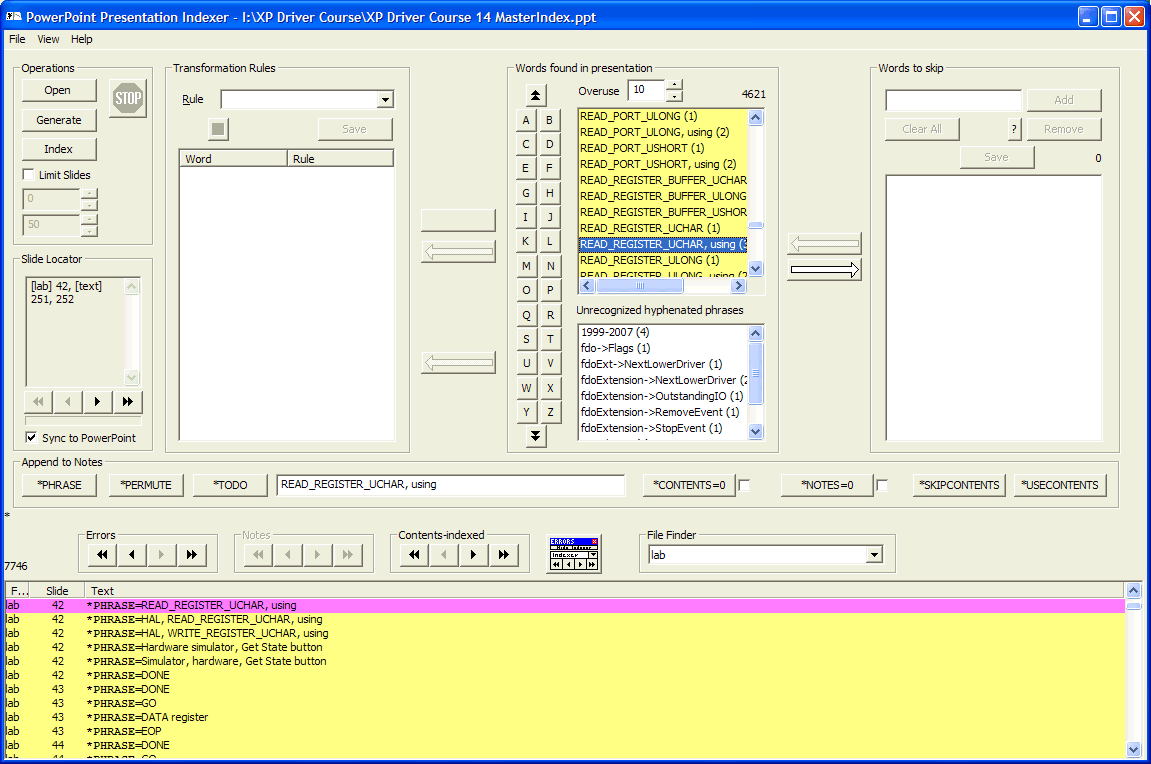
The main display has several interesting items displayed when there are multiple files.
Note in the Slide Locator, the alias names are displayed before the sequences of related slide numbers. In the bottom display, the alias names are listed in the left column of the display. The File Finder control is active, and will reflect what file is selected by displaying its alias name, but also, selecting an alias name in this box will position you at the first slide for that file.
This lists all the files which have been indexed. It is disabled if only one file has been indexed (no *INCLUDE directives). However, with multiple presentations being indexed, selecting the name here (the alias name), the index window will be scrolled to the first line indexed for that presentation..
File names can be very long. When the page numbers are shown in the index, they will be preceded by the "alias name". By default, the alias name is the filename part of the file (excludes the path and the .ppt). However, even a long file name will be inconvenient to have in the index. Therefore, a file can have a "short" name, an alias.
The alias can be supplied by two different methods. One can be when the *INCLUDE= directive is given. The syntax is
*INCLUDE=filename>alias
and any reference to the filename that is needed in the index uses the alias.
The other method is to supply, in a file, the directive
*ALIAS=aliasname
An error will be generated if there is an attempt to assign more than one alias to a file, and only the first alias will be used.
The "file" column listed in the bottom list control is the "alias name". However, hovering the mouse over the alias name will display the complete file name as a flyover help window:
With the notion of nested files, the only single progress bar no longer captures what is happening. Therefore, I created a modeless progress dialog that shows the progress through nested files. This shows that the one-and-only slide of the master PowerPoint index presentation has been read, but we are only partway through the detailed study of one of the included files. If the included file contains another included file, then a third progress bar would be shown showing the nested progress.

The index is decorated with the name of the file, or its alias, to indicate which presentation the words are found in. For example, one of my presentations comes with a text and supplemental lab notes. Both are indexed by doing
*INCLUDE=XP Driver Course 14.ppt>text *INCLUDE=XP Driver Course Lab 14.ppt>lab
An excerpt from the output is
| STATUS_ACCESS_VIOLATION
[text] 1250
STATUS_BUFFER_OVERFLOW [lab] 47, [text] 363 STATUS_BUFFER_TOO_SMALL [lab] 47, [text] 363, 364 STATUS_CANCELLED [text] 746, 1621, 1622 STATUS_DATA_ERROR [lab] 47, [text] 363 STATUS_DATA_LATE_ERROR [lab] 47, [text] 363 STATUS_DATA_OVERRUN [lab] 47, [text] 363 STATUS_DATATYPE_MISALIGNMENT [text] 1251 STATUS_DELETE_PENDING [text] 1191, 1213 STATUS_DEVICE_CONFIGURATION_ERROR [lab] 47, [text] 363 STATUS_INSUFFICIENT_RESOURCES [lab] 47, [text] 363, 572-1185 STATUS_INVALID_BUFFER_SIZE [lab] 47, [text] 363 |
The Table Of Contents (TOC) now contains a large dividing bar showing the split where each file is included. The TOC order is the order-of-inclusion, so if you are creating a "master indexing file" to name all your presentations, the order in which you place the *INCLUDE directives is the order they will appear in the TOC. However, if a file has no *HEADINGn directives, it will not appear in the TOC at all.
| Table of Contents | |
|
lab text |
|
1 |
Introduction |
15 |
Device Drivers |
21 |
NT Overview |
46 |
Application Level I/O |
| ... | |
2 |
WinDbg |
22 |
Lab setup |
24 |
Lab Resources |
26 |
Lab 1 |
| ... | |
| Name.Extension | Type | Contents |
| name.ppt | Input | PowerPoint presentation |
| name.nul | Input/Output | The list of null-words (words which are not indexed) |
| name.rule | Input/Output | The list of transformation and substitution rules |
| name.htm | Output | Main index file |
| name_ix.htm | Output | Left frame file, contains alphabetical index |
| name_ct.htm | Output | Right frame file, contains actual index text |
| name_toc.htm | Output | Right frame file, contains table of contents |
| name_hdr.htm | Output | Header frame |
| name_ftr.htm | Output | Footer frame, when present |
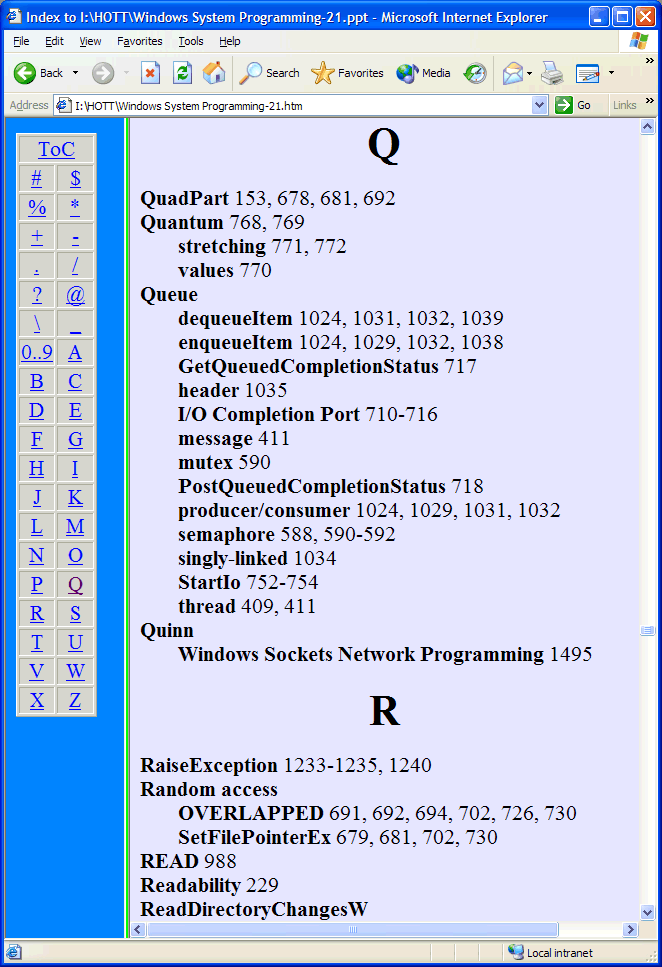
Here's a rather poor-quality screen shot of the kind index produced. But click on it to go to a live index!
(Single file version) |
Source Code Download: Get the complete
source. The source is a Visual Studio .NET 2003 MFC project.
Build it from scratch. Note that this is for the original version,
which did not support many of the features here including indexing multiple
presentations. Want to learn more about the inner workings of the program? Go here to see an article on the implementation! |
|
(Single file version) |
Executable Download: Not a programmer? Don't have Visual Studio? Trust me enough? This is the .msi file that will install the executable on your machine. |
| (Multifile version) |
Source Code Download: Get the complete source. The source is a Visual Studio .NET 2003 MFC project. Build it from scratch. This is the version described by this page. However, it is still officially a "beta" release. Please report any problems you have with it. |
| (Multifile version) |
Executable Download: Not a
programmer? Don't have Visual Studio? Trust me enough?
This is the .msi file that will install the new executable on your
machine. Note that if you have the Single File version already
installed, you will have to uninstall it before installing this version.
If you have version 2.0, you will have to uninstall it to install version
2.2. Want to learn more about the inner workings of the program? Go here to see an article on the implementation! |
I already have ideas for future work. These include
For a complete change log based on detailed point release versions, check here.
| Date | Changes |
| 27-Sep-07 | Version 1.2 released |
| 12-Oct-07 | Version 2 released. New features include
|
| 2-Nov-07 | Added *HEADING1 and *HEADING2 keywords and table-of-contents output |
| 5-Nov-07 | Added *TODO and error displays |
| 7-Nov-07 | Added multilevel indexing |
| 6-Jan-08 | Added *HEADING3 |
| Added *INCLUDE | |
| Added floating button box (makes it easier to use on single-monitor systems) | |
| Added header and footer to frame set of generated index (footer is optional and only present in multi-presentation indexing tasks) | |
| Added file-finder dropdown | |
| Added flyover help for alias-to-filename, error messages, and lengthy word list, skip list, and hyphenation list | |
| List boxes have flyover help for long lines | |
| Better error detection for out-of-range numeric values, non-numeric text in numeric values, and omitted text | |
| Added quick-search capability to the word list | |
| 29-Dec-09 | Cleaned up several bugs |
| Added ability to include all slide titles in Table-Of-Contents | |
| Added "Read HTML" button to launch browser or refresh existing presentation | |
| 30-Dec-09 | Version 2.2 released |
![]()
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.
 The Stop icon is enabled whenever there is
background processing. Note that clicking the Stop button may
not cause the program to stop immediately, because there may already be
queued messages that must be processed; it merely stops the thread from
queuing up more information to be processed. Once the information
has been processed in the background, you may have to wait for the
foreground to absorb the data.
The Stop icon is enabled whenever there is
background processing. Note that clicking the Stop button may
not cause the program to stop immediately, because there may already be
queued messages that must be processed; it merely stops the thread from
queuing up more information to be processed. Once the information
has been processed in the background, you may have to wait for the
foreground to absorb the data. Beginning and End buttons move you to the first and last
instances of the word. The Next and Prev buttons move to the next or
previous line that contains the selected word. Note that this is not
the next or previous slide, but the next or previous
line. Thus the Next button will
move to the first to the second to the third instance of a word on a
slide.
Beginning and End buttons move you to the first and last
instances of the word. The Next and Prev buttons move to the next or
previous line that contains the selected word. Note that this is not
the next or previous slide, but the next or previous
line. Thus the Next button will
move to the first to the second to the third instance of a word on a
slide.