
Understanding Processor Affinity and the Scheduler
|
|
Home |
 |
Back To Tips Page |
|
|
Understanding Processor Affinity and the Scheduler
|
|
Oh where, oh where has my little thread gone...oh where, on where can it be?
Threads run. But where do they run? They run on a processor. But which processor? And could we do something interesting if we could control which processor the threads were running on?
The answer is that yes, in some cases, we can really do interesting things. But you do have to be careful; try to get too cute and you could actually get worse performance than you would if you left everything alone.
Normally, processors and threads are considered as interchangeable pools. If you have n compute-bound threads, and n CPUs in your system (and that's logical CPUs, for those of you with hyperthreading), then in the best-of-all-worlds, each thread is running on a processor. Processor utilization is 100% on each processor, and you have maximum throughput.
But this is rarely the case in reality. In reality, we have m >> n (in mathematical notation, not C notation, that means "m is much greater than n") threads, and so we don't get all the processor cycles devoted to our thread.
A question that came up a while ago in the newsgroup was "how can I get to use 100% of my computing power to do my task?" The simple answer is, "You can't. And you shouldn't." You can't get all the CPU cycles because there is always some thread that has higher priority than a user thread. For example, kernel threads for device drivers, and in particular, the kernel threads used by the file system, always have higher priority than normal process threads. System threads normally run in the priority range of 16..31, whereas user threads are limited to the range 1..15 (0 is a special case and not available to user threads).
This program explores the relationships you can set up between process priority class and thread affinity to produce various kinds of results. The plot below shows an example where the process on the top plot is running at normal priority class, the one in the middle at above-normal priority class, and the one at the bottom at normal priority class with different thread affinities than the top plot. This image is small so it downloads readily, but the plot area and the window can both be resized to show maximum amounts of information.
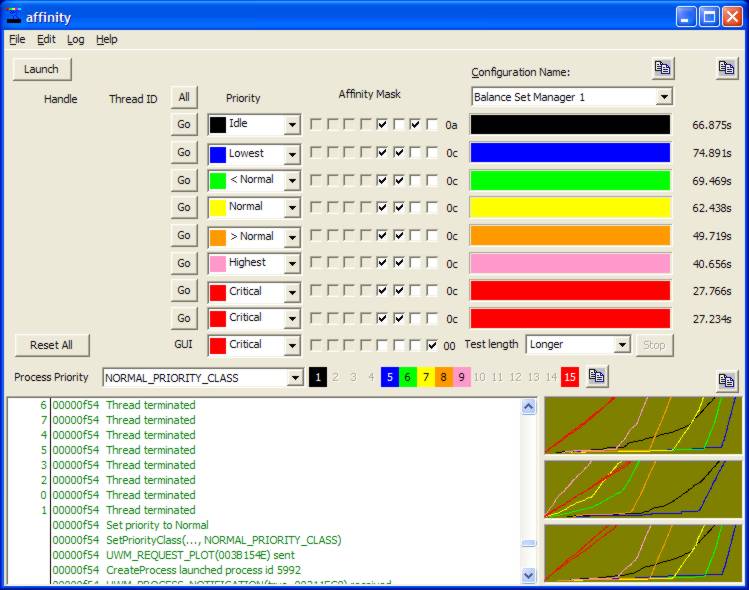
As to why you shouldn't, well, you mess over the user something ferocious. For example, the GUI can be effectively shut down. So if the user tries to click on the "stop" button, well, it is barely going to happen. And it will be an unpleasant experience for the user.
Been there, done that.
Some years ago I was working on an RS-485-based communication system. I had to respond really quickly to serial port input; in particular, there were time-critical responses that had to be made. Unfortunately, I kept missing the timing window. So the solution was simple: boost the priority of the thread. So I boosted it the maximum amount, +2 over the nominal priority. It worked really well in terms of the RS-485 communication. But it didn't work so well with respect to the user interface. I clicked the "Start" button and the communication started. But then the mouse became incredibly sluggish. I would move the mouse through some large distance, and after a while the cursor on the screen would follow the motion. Even getting the cursor to land on the "Stop" button was difficult, because I kept overshooting it. Finally, I got the cursor on top of the button. I clicked the mouse. And then I waited. And waited. And waited. Finally, the button went down. Then I released the mouse button. And waited. And waited. And waited. The button popped back up. Suddenly, I had control again.
What had I done wrong?
What I'd done wrong was set the "intercharacter" time on the serial port to 20ms. So if there was no data on the serial port, the I/O operation completed anyway, after a 20ms delay. Note that a 20ms delay is the scheduler timeslice delay. When I boosted this thread 2 points, it kept coming out of I/O wait just in time to run again; so there was no time to actually interact with the GUI. A very unpleasant experience. I fixed it by setting the intercharacter timeout to 100ms, because I realized that a well-formed packet had no intercharacter delays, and if a packet were ill-formed, waiting 100ms to discover it was wrong wasn't going to hurt.
I once had someone explain to me that those silly things like mutexes and semaphores weren't necessary. "I can do it all with scheduler priorities," he explained. "I make one thread be high-priority, and the second thread low-priority, and the second thread can't run until the first one is completed."
I explained that this could not work. He didn't believe me. He got really obnoxious about it, in fact. But he was completely wrong, for reasons that should be obvious.
Consider: if I have two processors, and two threads, those two threads might be the only two threads that can run in the system. Therefore, his high-priority thread and low-priority thread will run concurrently. He assured me that "I will never have to worry about multiprocessors. They're too expensive". Well, for the last few years, multiprocessors, at least in the form of hyperthreaded Pentium-4s, have been standard in the home computer world. And AMD and Intel are now delivering multicore processors; Intel is delivering dual-core processors for laptops! The world of multiprocessors is here to stay. So you can never assume you won't be running on a multiprocessor.
Furthermore, there is a special, high-priority kernel thread called the "balance set manager". Its job is to wake up every so often and check to see if there are any very hungry threads in the system (a thread whose priority is so low that it is never given a chance to run is called a "starved" thread). If the balance set manager finds a thread which hasn't run in a while (the definition of "while" depends on a lot of parameters, and is somewhere between 3 and 4 seconds on most systems), it is boosted to priority 15 and given a double-length timeslice. So even on a uniprocessor, the scheduling-is-synchronization technique could never have worked.
You can't measure a system using a mechanism that requires resources in the system. The resource usage of the measurement tool perturbs what is being measured. The only ways you can get absolutely true measurements are by doing things like monitoring CPU bus traffic. Other than the minor detail that systems that can do this run into the hundreds of thousands of dollars just to "buy into" them, and they work for exactly one model of CPU (pods for each CPU can run tens of thousands of dollars) there's nothing wrong with this approach. But it is impractical for any but the most extreme cases of performance measurement. Therefore, we have to accept some perturbation of what is going on.
I tired to minimize this with a number of mechanisms. For example, I create all the threads suspended. Then I perform all the per-thread initialization of the graphing data structures, which can include freeing up large numbers of point-plot objects. When all threads have achieved a "setup" state, only then will I release them. During the time I am releasing threads, I set the thread priority of the GUI thread (where this is done) to be the highest feasible priority for the thread. In this way, releasing a thread with ::ResumeThread will likely not be preempted by the thread that was just released. After the threads have been released, I set the GUI thread priority back to its desired level.
In the case of multiple processes, I had to make sure this worked with all child processes; so that I would request all child processes release their threads at the same time.
I'm not going to claim the code here is maximually robust; closing a running child with the task manager could result in the main process hanging or producing strange results. Since this is a testbed program, it is expected that such silly things will not be done by the user. Clean shutdowns should work correctly. I don't guarantee its behavior under pathological conditions, although I have tried to do my best to make it fairly solid. The engineering required to make this "production quality", the kind of quality I might apply to a server process, for example, simply isn't justified in a modest project like this.
In addition, the experiment can be treated as working with n-1 processors, where one processor is designated as the "GUI" thread affinity. Thus, the GUI thread will run on this one processor and the work is done by the remaining n-1 processors with minimal interference from the GUI thread. For best response, the GUI thread should be set to be a "Time-Critical" thread. For least interference, the GUI thread should be set to be an "Idle priority" thread.
In the simplest mode, simply launch the program. It recognizes up to 8 CPUs, and allows up to 8 test threads to be specified. The GUI thread is a ninth thread, and its attributes can be specified.
The parameters that can be specified for a thread are its processor affinity mask, selected by clicking the check boxes for the processors. Processor 0 is the rightmost processor. The check boxes represent the low-order 8 bits of the thread affinity mask.
The dropdown selects the thread priority. The thread priority is always relative to the process priority class.
The thread priorities are not usually absolute priorities, but are computed as -2, -1, 0, +1, and +2 relative to the "normal" priority. The "normal" priority is based on the process priority class. The process priority class can be set to idle, below normal, normal, above normal, and highest. In addition, independent of the process priority class, two absolute thread priorities are always supported: idle and time-critical.
The process priority class determines the absolute range of thread priorities that can be selected.
When a thread has affinity to at least one processor, it can run, and its "Go" button becomes enabled. Clicking "Go" will run that thread, and that thread only.
When one or more "Go" buttons are enabled, the "All" button is enabled. When the "All" button is clicked, all threads are released, as quickly as possible.
Each thread has a loop from 0 to 99. At the end of this loop, a message is posted indicating the current time (using the system ::GetTickCount) and and the amount of information computed. The loop itself contains a nested computationally-intense loop. The duration of this loop is selected by the test length, which has terms such as "Shortest", "Shorter", "Short", "Regular", "Long", "Longer" and "Longest". There's a length called "Amazingly long" which allows you to run some other compute-intensive application and watch the effects on the experiment.
As a thread is computing, its progress bar shows how many of the outer loops have completed.
When the thread completes, the actual amount of time spent performing that computation will be displayed. The effect is that if you have a single CPU and a high-priority thread and idle=priority thread, you will see that the high-priority thread runs to completion, then the low-priority thread runs. The completion time of the low-priority thread, from release to completion, will be the sum of the high-priority thread time and the idle-priority thread time.
But with multiple-priority threads and multiple processors, and tweaking of the affinities, you can see all kinds of fascinating artifacts of the scheduler.
Whatever settings you create will be remembered. The settings are saved each time they are changed. While this makes it convenient to run an experiment over and over, it can make it inconvenient to modify an experiment, since the affinities, thread priorities, process priority class, and experiment length will all have to be changed. And, if an interesting result is noted, you would have to write everything down so you can try it again.
This is painful. Why should a person track and remember what a perfectly good computer can already remember for you?
So I added the concept of "configuration". A "configuration" represents a particular set of control settings, and can have a name. When you create a new configuration name, it takes whatever your current settings are and makes them the initial settings of the new configuration. There is a "Reset all" button that returns all values to their nominal default settings.
It would be nice to run threads at all kinds of settings, but this is not possible; you are restricted to 7 absolute priority levels for threads in any given process. Although you are free to change the process priority class, this merely gives you 7 other levels. So you can't run a priority 12 and priority 2 thread in the same mix.
To fix this, I allow the spawning of "subprocesses". A subprocess cannot itself spawn other processes, and it contains no graph. A set of graphs will be displayed in the master copy. Each individual child process will have a log and a complete set of parameters.
Shown below are the process priority classes and their associated possible thread priority values.
| Selection and display | Idle | Lowest | Below Normal | Normal | Above Normal | Highest | Time Critical |
| 1 | 2 | 3 | 4 | 5 | 6 | 15 | |
| 1 | 4 | 5 | 6 | 7 | 8 | 15 | |
| 1 | 5 | 6 | 7 | 8 | 9 | 15 | |
| 1 | 8 | 9 | 10 | 11 | 12 | 15 | |
| 1 | 11 | 12 | 13 | 14 | 15 | 15 |
The problem with having a set of stored configurations is that it is hard to have to go into each child and select a new configuration. So there is a simple rule supported for handling child processes: if a configuration called "myconfig" is selected in the master process, when a child is spawned, the first child process will automatically try to use the configuration "myconfig-1", the second "myconfig-2", and so on. This is a bit of a kludge, but works quite well for small experiments. The simplified rule is that if a configuration "myconfig-n" is not found, then it will revert to the "base configuration" "myconfig".
Once a child has been spawned, its configuration is set; changing the configuration in the master will not change the configurations in the child processes. A change made to a configuration becomes definitive, but any changes do not become visible in any processes sharing this configuration unless they reselect it. (Note to self: change this!)
There is a special, high-priority kernel thread known as the "Balance Set Manager". It's job is to prevent thread starvation. A thread is starved when it hasn't got the CPU in a "long time", even though it is feasible to run. Here are a few snapshots take of a balance set manager experiment. In this example, the process priority class was normal priority, all the threads except the GUI thread were bound to a single processor, and we see that in spite of the fact that the high priority threads were compute bound, there are points at which the other threads got a shot at running.
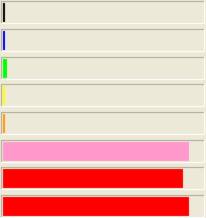
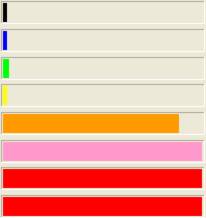
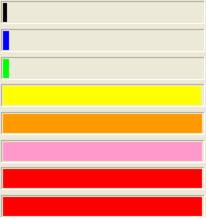
Note that even the idle thread gets a chance to run now and again. This can be seen in the final graph image, where the point where the thread really starts computing is offset from 0. Without the Balance Set Manager, all lines would have been at 0 until all higher priority threads had finished..

This program illustrates a number of implementation techniques. Some of these techniques are described in other essays on implementation techniques.

![]()
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft. In fact, I am absolutely certain that most of this essay is not endorsed by Microsoft. But it should have been during the VS.NET design process!