
Asynchronous I/O
and
The Asynchronous
Disk I/O Explorer
|
|
Home |
 |
Back To Tips Page |
|
Asynchronous I/OandThe AsynchronousDisk I/O Explorer |
|
Asynchronous I/O often is a mystery. Why would you want to use it? How do you use it? When would you want to use it? What are its properties?
More importantly, how can you build asynchronous I/O mechanisms that are easy to construct, debug, maintain, and reason about? If the wrong choices are made, you could end up with an asynchronous mess. Alternatively, if you don't use asynchronous I/O, you could end up with threads that have unfortunate side effects, such as the inability to shut them down, or the blocking of a thread that keeps it from doing something important.
This essay addresses these issues. It has two sections:
The fundamental nature of asynchronous I/O is that it nominally returns immediately to the program that issued the call, without blocking the thread. This is not always true, by the way, a fact which we will discuss later in this article. But the key idea is that you will not delay the thread unduly. This is often a handy thing to be able to do in, for example, the main GUI thread, or in the main thread of a server.
It is often better to do simple asynchronous I/O in a thread, rather than synchronous I/O, if the device has an unbounded wait time (for example, a network connection or a serial port are prime examples of this, but many USB or 1394 devices are also characterized by unbounded wait times). If a thread is blocked on I/O wait in the kernel, it can't be shut down. Asynchronous I/O will provide a simple mechanism for allowing a thread to shut down.
It servers other purposes as well. For example, it is necessary for full-duplex devices because the I/O Manager will "gate" I/O requests in synchronous mode so that there is not more than one of them at a time delivered to the device. To use a serial port in full-duplex mode, you must open it in asynchronous mode.
A problem which arises from time to time deals with very high-performance devices. The "round-trip" time for a ReadFile request, for example, can be tens to hundreds of milliseconds. This means that it is often likely that you will suffer from data overruns. By using asynchronous I/O, you can rely on the fact that nearly all device drivers will queue up the incoming I/O requests, and will, if properly written, start the next I/O request from the internal queue before completing the current I/O request (for those of you doing drivers, this means you do either IoStartNextPacket or your appropriate dequeue-and-initiate mechanism before doing the IoCompleteRequest).
In many cases, using asynchronous I/O allows you to create programs which are actually easier to reason about than programs using synchronous I/O. This is because you can often create a single thread handling asynchronous I/O which is logically simpler to write than trying to figure out how to make synchronous I/O work, or using separate threads for everything. Using too many threads creates a different kind of system load, which might have very serious consequences in terms of overall system performance.
Asynchronous I/O on disk files is a bit tricky; asynchronous I/O is most commonly used to handle non-file-oriented hardware devices, many which have characteristics similar to those of serial ports.
There are several ways of handling asynchronous I/O.
When an I/O operation is started on an asynchronous handle, the handle goes into a non-signaled state. Therefore, when used in the context of a WaitForSingleObject or WaitForMultipleObjects operation, the file handle will become signaled when the I/O operation completes. However, Microsoft actively discourages this technique; it does not generalize if there exists more than one pending I/O operation; the handle would become signaled if any I/O operation completed. Therefore, although this technique is feasible, it is not considered best practice.
When you call CreateFile, there is a flags-and-attributes parameter (the sixth parameter). If you "or" in the value FILE_FLAG_OVERLAPPED, the handle is an asynchronous handle. It can only be used for asynchronous I/O operations, that is ReadFile, WriteFile and DeviceIoControl must have a non-NULL last parameter which is a pointer to an OVERLAPPED structure. You can also use ReadFileEx, WriteFileEx and DeviceIoControlEx, which we will discuss later.
If you do not specify FILE_FLAG_OVERLAPPED, you have a synchronous handle. You can only use ReadFile, WriteFile and DeviceIoControl, and these will always be synchronous calls, even if you specify a non-NULL OVERLAPPED pointer in the call. You cannot use ReadFileEx, WriteFileEx, or DeviceControlEx.
A handle retains its synchronous or asynchronous nature for its entire lifetime. You cannot open an asynchronous handle and suddenly decide you would like to do synchronous I/O, or a synchronous handle and decide you would like to do asynchronous I/O. The only way to switch modes is to open a handle of the desired type. Note that this may require that you close the existing handle based on the sharing rights you specify.
Whenever asynchronous I/O is performed, an OVERLAPPED structure must be referenced in the I/O operation (it is the last parameter to ReadFile, WriteFile, and DeviceIoControl). For file-based devices, the OVERLAPPED structure includes the "seek position" which specifies the byte offset from the start of the file where the I/O operation applies. Unlike synchronous I/O, where disk I/O has an implicit "current file position", which is set by SetFilePostion (the underlying API of fseek or CFile::Seek), and advanced implicitly by ReadFile and WriteFile operations (the underlying API calls for operations such as fread, fwrite, CFile::Read, CFile::Write, CStdioFile::ReadString, CStdio::WriteSting and so on), asynchronous I/O requires that in a file-based handle you must provide the explicit position yourself, in each and every I/O operation, and to proceed sequentially through a file, you must add the bytes-read value or bytes-written value to the current position variable you maintain, and supply that value as part of the OVERLAPPED structure.
In antiquated systems, files could only have 232 bytes. This is not terribly interesting, being too small for most practical databases, and many data files. So when Windows was created, it was created with files that can be 264 bytes in a file. This seems comfortable enough for most practical purposes.
According to http://www.seagate.com/newsinfo/about/profile/index.html, in 2004 Seagate produced 6.6 petabytes of disk storage. That's 6.6×1015 bytes. A single file of 264 bytes is 4.6 exabytes, or 4.6×1018 bytes. Unless Seagate tremendously increases their capacity, to have a single file of 264 bytes would require about 700 years of the entire output of Seagate corporate disk production, assuming that the number of bytes per year is constant. Remember, that's for just one file. Of course, you'd probably want to put something like this on a RAID array, which will take a lot more disks... (OK, those of you who have studied the curve of disk density increase will say that indeed, I'm being somewhat pessimistic, but I'm feeling lazy and haven't worked out the numbers based on increasing disk density. If you want to work this out and send me the computation based on current trends, I'll be glad to include it here along with an attribution to your work. But remember, whatever number you come up with applies to just one file. We haven't taken into account how long it would take to write 264 bytes, even at maximum bandwidth. For example, if you have Ultra320 SCSI, capable of writing 320MB/sec, it would take 1.43 1010 seconds to write all that data, ignoring seek time and rotational latency. With a little bit of arithmetic, I get somewhat over 450 years of raw data transfer time, just to write a single 264 byte file. So maybe the delay in acquiring the disk drives is not going to be the bottleneck. Oh yes, state of the art today is the 0.5TB drive, so it would take 9.2 million of these drives to populate the 64-bit file space, and the power consumption is 13W (typical) or 120MW for a simple non-redundant storage array. That's 6% of the total output of Hoover Dam, or enough to power over 80,000 typical homes).
In a very unfortunate mistake in the history of Windows, there was no native 64-bit data type in the C compiler. So those lovely 64-bit file lengths, file positions, and other 64-bit values have to be expressed in a very clunky way, as two 32-bit values. We are nearly 20 years from that decision, and nobody has had the guts to get rid of all of these artifacts (there are some new APIs, but why don't we have an OVERLAPPEDEX structure with a 64-bit offset? For that matter, when the OVERLAPPED structure was generalized, it would have been trivial to add this feature...)
The OVERLAPPED structure looks like this
typedef struct _OVERLAPPED {
ULONG_PTR Internal;
ULONG_PTR InternalHigh;
DWORD Offset;
DWORD OffsetHigh;
HANDLE hEvent;
} OVERLAPPED, *LPOVERLAPPED;
(The real truth is a bit more complex, but this is the documented interface).
To do asynchronous I/O on a file-oriented device, the Offset and OffsetHigh values must be set to represent the full 64-bit value. The general technique for doing this is to use a LARGE_INTEGER type, which overlays a LONGLONG (64-bit integer) value with two 32-bit values.
typedef union LARGE_INTEGER {
struct {
DWORD LowPart;
LONG HighPart;
};
LONGLONG QuadPart;
};
The way this is used violates some of the C "best practice". In "best practice", if you have a union, and you assign to one member of the union, you are not supposed to fetch from a different member of the union; this is not defined portably.
"Unions are used in a nonportable fashion any time a union component is referenced when the last assignment to the union was not through that component” Harbison & Steele, C: A Reference Manual, Fourth Edition, p.14.
A similar warning can be found in Stroustrup, The C++ Programming Language, Third Edition, p.842.
The way to use this is to maintain the 64-bit position in the QuadPart, and perform the assignments using the LowPart and HighPart members, such as
LARGE_INTEGER pos; // pos,QuadPart = ...some value... OVERLAPPED * ovl = new OVERLAPPED; ovl->Offset = pos.LowPart; ovl->OffsetHigh = pos.HighPart;
The other important member of the OVERLAPPED structure is the hEvent member. This must either be NULL, or the handle of an Event object created by CreateEvent as a manual-reset event. When the handle is non-NULL, it will become non-signaled when an I/O operation starts and will become signaled when the I/O operation completes. Thus, it can be used in a WaitFor... operation to determine when the I/O operation has completed.
Note that one of the common errors is the case where an Event is not required. If you fail to set this member to NULL, which will result in the I/O operation failing (except for ReadFileEx or WriteFileEx) and GetLastError will return ERROR_INVALID_PARAMETER.
It is very important that the OVERLAPPED structure remain intact for the entire duration of the I/O operation. This means that in nearly all cases the OVERLAPPED structure must be heap-allocated, and you are responsible for disposing of it when you are finished with it. Otherwise you have a storage leak. In the examples that follow, techniques for doing this reliably will be illustrated.
This is the simplest way to perform asynchronous I/O. However, it presents certain problems of keeping track what is going on, and I prefer to use it only in very restricted scenarios.
There are two variations of the Event handle paradigm. In one scenario, the number of Events is fixed at compile time and never, ever changes. This is the easiest scenario. The other scenario is one in which the number of event handles can vary dynamically as I/O operations are performed. I find the use of the Event handle paradigm inappropriate in this case, for reasons I will explain.
Let's look at the very simplest case, which I call "pseudo-synchronous I/O". This is often used for devices such as serial ports. In this case, you initiate the asynchronous I/O operation, then simply block waiting for it to finish.
How does this do any good? You're doing synchronous I/O, only clumsier, right? No, there are two major payoffs here. First, for a serial port to operate in full-duplex mode, the handle must be an asynchronous handle, even though you would like to use it in a nominally synchronous fashion.
There are two ways to wait on an Event handle. One is use WaitForSingleObject (we're talking the simple case here, so we'll defer discussion of WaitForMultipleObjects), and the other is to use GetOverlappedResult. Typically, if you use GetOverlappedResult you will not need to use the WaitForSingleObject call, but if you use WaitForSingleObject, you will ultimately need to call GetOverlappedResult to get the details. Note that GetOverlappedResult does require that there be a manual-reset event in the OVERLAPPED structure.
A typical piece of code that would do an asynchronous ReadFile would look like the following code. This code is intended to be run in a separate thread, and it handles input from a single serial connection. If you need to support multiple serial ports, you would need to run separate threads, one per serial port, and include information identifying the port on which the error or data occurred. This is left as an Exercise For The Reader.
OVERLAPPED ovl;
ovl.hEvent = ::CreateEvent(NULL, TRUE, FALSE, NULL);
LPBYTE buffer = new BYTE[bufferSize];
while(running)
{ /* read loop */
if(buffer == NULL)
{ /* allocation failure */
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)ERROR_OUTOFMEMORY);
running = TRUE;
continue;
} /* allocation failure */
BOOL b = ::ReadFile(handle, buffer, bufferSize, &bytesRead, &ovl);
if(!b)
{ /* failed */
DWORD err = ::GetLastError();
if(err == ERROR_IO_PENDING)
{ /* pending */
b = ::GetOverlappedResult(handle, &ovl, &bytesRead, TRUE);
if(!b)
{ /* wait failed */
DWORD err = ::GetLastError();
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)err);
running = FALSE;
continue;
} /* wait failed */
} /* pending */
else
{ /* some other error */
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)err);
running = FALSE;
continue;
} /* some other error */
} /* failed */
if(bytesRead > 0)
{ /* has data */
wnd->PostMessage(UWM_HAVE_DATA, (WPARAM)bytesRead, (LPARAM)buffer);
buffer = new BYTE[bufferSize];
} /* has data */
} /* read loop */
delete [ ] buffer;
wnd->PostMessage(UWM_THREAD_DONE);
::CloseHandle(ovl.hEvent);
There are several symbols not defined in the above example. The wnd variable is a CWnd * variable which will represent the window to which the message is to be posted. The UWM_ symbols are references to messages, by my preference, Registered Window Messages (see my essay on Message Management for more details). The running flag is a value which can be set to cause the loop to exit. The running should be declared as a VOLATILE BOOL and it must be set TRUE before the thread is started.
You may look at this and say "Well, there's no way to shut the thread down because you block forever on the GetOverlappedResult call". In general, this might be true, but in the specific case of a serial port, there are timeouts involved. It is perfectly valid to have the ReadFile on a serial port complete with a TRUE result and 0 bytes of data transferred. Thus, there is no "indefinite" blocking on a serial port, unless you have disabled timeouts, which should be considered a Really Bad Idea.
Note also the requirement that the OVERLAPPED structure exist for the duration of the I/O operation is met, even though the OVERLAPPED structure is allocated on the stack. This is because the function cannot exit while there is pending I/O, so the local variable will persist as long as there is pending I/O.
The simple approach works fine if the device is like a serial port with a known upper bound on how long it can block. This solution is only slightly more complex. The problem with indefinite lengthy blocking is that it would be impossible to shut the thread down. To deal with this, we use two Event objects, and wait on both. The trick here is that the first element of the array is the shutdown event, and this is so that if the shutdown event is ever set, the WaitFor will indicate that a shutdown is intended, even if there is concurrent completion of the I/O operation (otherwise, it would be awkward to do a thread shutdown if the the device was not blocking).
OVERLAPPED ovl;
ovl.hEvent = ::CreateEvent(NULL, TRUE, FALSE, NULL);
LPBYTE buffer = new BYTE[bufferSize];
HANDLE waiters[2];
waiters[0] = shutdown;
waiters[1] = ovl.hEvent;
BOOL running = TRUE;
while(running)
{ /* read loop */
if(buffer == NULL)
{ /* allocation failure */
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)ERROR_OUTOFMEMORY);
running = TRUE;
continue;
} /* allocation failure */
BOOL b = ::ReadFile(handle, buffer, bufferSize, &bytesRead, &ovl);
if(!b)
{ /* failed */
DWORD err = ::GetLastError();
if(err == ERROR_IO_PENDING)
{ /* pending */
switch(::WaitForMultipleObjects(2, waiters, FALSE, INFINITE))
{ /* waitfor */
case WAIT_OBJECT_0: // shutdown
running = FALSE;
::CancelIo(handle);
continue;
case WAIT_OBJECT_0+1: // I/O complete
break;
default:
{ /* wait failed */
DWORD err = ::GetLastError();
ASSERT(FALSE);
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)err);
running = FALSE;
continue;
} /* wait failed */
| /* waitfor */
b = ::GetOverlappedResult(handle, &ovl, &bytesRead, TRUE);
if(!b)
{ /* wait failed */
DWORD err = ::GetLastError();
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)err);
running = FALSE;
continue;
} /* wait failed */
} /* pending */
else
{ /* some other error */
wnd->PostMessage(UWM_REPORT_ERROR, (WPARAM)err);
running = FALSE;
continue;
} /* some other error */
} /* failed */
if(bytesRead > 0)
{ /* has data */
wnd->PostMessage(UWM_HAVE_DATA, (WPARAM)bytesRead, (LPARAM)buffer);
buffer = new BYTE[bufferSize];
} /* has data */
} /* read loop */
delete [ ] buffer;
wnd->PostMessage(UWM_THREAD_DONE);
::CloseHandle(ovl.hEvent);
Note that the major change from the previous example was the inclusion of the WaitForMultipleObjects. The shutdown variable represents a HANDLE to a manual-reset event created in the non-signaled state. It will be set to the signaled state (using SetEvent) when the thread should be shut down. The WaitForMultipleObjects has its wait-for-all flag (the third parameter) FALSE, meaning "wait-for-any"; it will come out of the wait if any of the handles become signaled. It is very important that this be a wait-for-any wait, otherwise, it can never come out of the wait when the I/O operation completes.
Note that although the GetOverlappedResult call is marked as infinite-wait, in fact it will never wait because it cannot be reached unless the WaitForMultipleObjects has allowed the thread to proceed because the I/O has completed.
As with the previous example, this is intended to be run in an auxiliary thread and perform its operations within that thread. The various parameters such as wnd and shutdown should probably not be static variables, but either passed in via a parameter structure pointer or be class members of a class, where this code is executing within the class instance. For details on how this is done, see my essay on worker threads.
Note that the running Boolean is no longer outside the function, but is a simple local variable declared inside the function.
First, let me state that I think this is a bad technique. It is hard to code, hard to manage, hard to debug, and hard to reason about. I'm not going to show any code, because the code is gratuitously complex. I believe that if this technique appears to be applicable, then one of any number of better techniques should be chosen instead.
The basic technique is to create an array of handles, one for each pending I/O operation (and, as described in the previous section, the [0]th element of the array would typically be a "shutdown event". to allow graceful shutdown). Thus, when any of the handles become signaled, the WaitForMultipleObjects will come out of the wait, with the index into the array of the signaled handle. When multiple handles become signaled concurrently, the index is always the lowest-numbered signaled handle index.
And there is one of the serious problems. Once the I/O operation is completed, unless you immediately initiate a new I/O operation using that Event handle (which is not a common way to handle such I/O), you will have to remove the handle from the array of handles. This means that all the handles above it (if there are any) will have to be "shifted down" to compress out the "hole" created by the removal of the handle. If the handle is left in place, it will remain signaled, and thus no I/O operation whose handle is of higher index will ever be recognized. You can't just leave it in, and you can't set it to NULL (if you do, the WaitForMultipleObjects will fail with the WAIT_FAILED result, and ::GetLastError will return ERROR_INVALID_HANDLE).
Next, the problem arises as to how to correlate a returned value with whatever should be done next. This involves having an array which is equivalent to the handle array, where the information for handle [i] will be found in the [i]th element of this array. This means that when the handle is removed from the handle array and the handle array is compressed, the corresponding element must be removed from the auxiliary array and this array must also be compressed. This adds complexity to the problem.
You will have to allocate a new handle for each I/O transaction, which means you are going to either doing a lot of ::CreateEvent and ::CloseHandle calls, which will create unnecessary overheads, or keep a "pool" of handles you want to reuse, and have to deal with what happens when you "run out" of handles in your pool, and you will need a pool that is thread-safe, either managed by a single thread, or properly synchronized using appropriate synchronization primitives. This is additional complexity you could do without.
But the other problems are more serious. For example, this solution does not scale well. There is a hardwired limit of MAXIMUM_WAIT_OBJECTS, which is currently 64. This is fairly small, and in general, if you need n handles, it is very likely you will need n + 1 handles, and at some point you exceed the number of handles that you can use in a WaitForMultipleObjects. You could use either callback asynchronous I/O or I/O Completion ports (which I think is the easiest solution to the problem).
You have to deal with starvation issues. If a fast-responding handle is placed low in the array, handles of higher index will never be serviced. So the naive approach would be to put this handle at the end of the array, allowing other handles that are not "hogging" the CPU to get responsiveness. But this could be true of any or all of the handles in the array, thus guaranteeing some form of starvation. If the slower-responding handles are placed lower in the array, you get what is called "priority inverstion", where the response time to the fast-responding handle is delayed by other, possibly lower-priority, handles. If these handles complete often enough, you are now starving the device which would like frequent service.
There are serious questions about how to create a thread that can have multiple pending I/O operations and still service them properly. If the thread is blocked on a WaitForMultipleObjects, it cannot initiate a new I/O operation, so how did all those operations get there? But if you time out so you have opportunity to add more I/O operations, then the frequency with which you can add them is gated by the timeout delay. If you have a 200ms delay, you can't have more than five opportunities per second to add new I/O requests (and thus add new elements to the array), unless operations are completing more often. Thus, your throughput is now limited by the timeout parameter. If you make the timeout interval smaller, your thread spends a lot of time executing but doing nothing but consuming CPU time, and stealing that time from other threads that actually have useful work to do.
In addition, the completed I/O operation can only be handled in the context of the thread that has come out of the WaitForMultipleObjects, which means that no matter how much excess computing capacity you have in a multiprocessor or hyperthreaded processor, you can't utilize it to increase your throughput. If you have 10 pending I/O operations that complete near-simultaneously, you can only handle them one at a time. This makes your 8-processor server handle I/O with as much effectiveness as a uniprocessor, which is not what you expected when you spent all that money to buy that expensive box.
Overall, I consider this about the worst possible solution to the problem of multiple asynchronous I/O operations with dynamic scaling.
Callback I/O is performed by having the operating system call a chosen subroutine when an I/O operation completes. This has several advantages over trying to do complex WaitForMultipleObjects scenarios, in that it scales well (there is no limitation to the number of concurrent operations that are pending), it has inherent anti-starvation properties (I/O callbacks are dispatched in first-in-first-out (FIFO) order), and it is easier to reason about. You don't have to maintain complex auxiliary structures to track an I/O operation, but can include the context in the OVERLAPPED structure, using a technique I will describe.
Callback I/O has a well-deserved bad reputation. In fact, the urban legend is that Dave Cutler, architect of both VMS and Windows NT, had been heard to remark "callback I/O will go into Windows over my dead body". We observe two things, first, that callback I/O exists, and second, Dave Cutler is very much alive. So how did this situation get resolved?
The classic example of callback I/O, which has been implemented in many operating systems, is exemplified by the Asynchronous System Trap (AST) of VMS. When a queued I/O operation was issued in VMS, a callback function was specified. When the I/O operation completed, that subroutine was called, as if it were an "interrupt handler" in user space. And therein were the seeds of disaster. Suppose that the application was running in the storage allocator. It has partially-unlinked a block of storage. The invariants of the storage allocator data structure are at this point not maintained, in fact, the storage allocator structures are basically trashed. Until the allocator operation completes, the integrity of the data structures cannot be guaranteed.
So in the middle of all this, an AST would occur. And the subroutine wants to allocate or free storage! So it calls the storage allocator. What follows Is Not A Pretty Sight. OK, you say, let's synchronize the allocator with the equivalent of a CRITICAL_SECTION or Mutex. Wrong. There are two ways synchronization primitives like this can work: with or without "recursive acquisition semantics". With recursive acquisition (as is implemented in Windows, for example), an attempt by a thread to acquire a lock depends on whether or not the thread has already acquired the same lock. In Windows, the thread is said to "own" the lock. So the thread locks the storage allocator, and in the middle of the allocator operation, the AST occurs. The called subroutine, which is executing in the context of the running thread, tries to acquire the lock. It gets it! Because the thread already owns the lock, of course it is allowed to re-acquire the lock, and it happily starts traipsing over the nominally protected structures. It Is Not A Pretty Sight. OK, you say, what if we did away with recursive acquisition semantics. Even in Windows we can do this by using a "binary semaphore", which is a semaphore whose minimum value is 0 and maximum value is 1. So we use a binary semaphore to protect the storage allocator. We lock it. The AST occurs, and the subroutine tries to use the allocator. Well, it can't acquire the lock, so the thread stops. It will resume when the allocator lock is released. But the allocator lock can't release until the storage allocator exits, and the storage allocator can't exit until the AST returns control, and the AST can't return control until it exits, and it can't exit until it can acquire the lock and complete its allocator operation, but it can't acquire the lock until it is released, and this can't happen until...well, you get the picture. This is a classic example of "deadlock", and in this case a thread has deadlocked itself.
What if it isn't an allocator, but some other code of yours? What if it is code in some function that you actually have no control over, such as the MFC library?
Well, you say, why not adopt the VMS solution (e.g., see http://en.wikipedia.org/wiki/Asynchronous_System_Trap) which was to disable ASTs before doing operations that would cause problems? Well, that's the real disaster in VMS. You never knew, when writing a callback function, whether or not it could interfere with any other part of the program, and, like the infamous COME FROM statement means that every statement in the source code must anticipate every side effect of every callback function. The result was a programming nightmare.
The design compromise that avoids all the problems of the VMS implementation is something called the alertable wait state. A thread is not able to process callbacks unless it is in the alertable wait state. Since no thread, in the middle of some critical operation, will enter this state, the points at which side effects can occur can be well-defined.
This is not a perfect solution. It introduces its own problems, which I will discuss shortly.
A callback I/O operation is initiated by using the operations ReadFileEx, WriteFileEx, or DeviceIoControlEx. These operations specify the address of a function to be called when the I/O operation has completed and the thread is in alertable wait state.
To enter alertable wait state, you must then call one of the functions that enters alertable wait state. These are WaitForSingleObjectEx, WaitForMultipleObjectsEx, and SleepEx. Once you have entered alertable wait state, any pending I/O operations will be dequeued. When all the pending callbacks have finished, the thread will immediately resume; the WaitFor...Ex or SleepEx will continue with the error return code WAIT_IO_COMPLETION.
Note that the hEvent member of the OVERLAPPED structure is not used, and you can use it to pass anything across the initiation-to-call boundary. Since hEvent is a HANDLE, this means it is large enough to hold a pointer, even in Win64. The contents of the hEvent are ignored by the I/O system when ReadFileEx, WriteFileEx, or DeviceIoControlEx are used.
The biggest problem with callback I/O is that alertable-wait-state issue. The total throughput will be limited by how often you manage to get the thread into the alertable wait state. If you fail to put it into alertable wait state often enough, you lose throughput. This means you need a loop that gets into the alertable wait state frequently enough that there is no bandwidth loss. It also means that if you are trying to do this in the main GUI thread, the activities involved in doing screen updates can delay the I/O handling.
It leads to a fair amount of complexity. The use of callback I/O is one of the few reasons you would need to override the CWinThread::Run method to replace the rather sophisticated code with code that uses MsgWaitForMultipleObjects(Ex). This is not something that even most experienced MFC programmers would choose to do, and should not be treated as a simple decision. It is far simpler to use I/O Completion Ports.
Finally, there is the issue of total throughput. The callback functions are executed, one at a time, in the context of the thread that initiated the I/O operation. This means that no more than one completion event at a time could be processed. In a large multiprocessor system, we have the problem that the WaitForMultipleObjects solution has: that excess CPU capacity can remain idle while one CPU has to work very hard to process all the concurrent I/O operations that may have completed near-simultaneously.
My favorite technique for doing asynchronous I/O uses I/O Completion Ports to handle the completion notifications. This has several advantages, which is why I favor them:
The basic idea of an I/O Completion Port is that it is a built-in queuing mechanism that can be coupled to I/O transactions. This is actually interesting, in that it is possible to use I/O Completion Ports simply as inter-thread queuing mechanisms by having no file associations and calling PostQueuedCompletionStatus to place entries in the queue. I discuss the use of this technique in my essay on using I/O Completion Ports for cross-thread messaging.
What you do is to create an I/O Completion Port using CreateIoCompletionPort. In the creation you can associate a file handle with the port, or you can add one or more file handles to the completion port at any future time.
When a handle is added to an I/O Completion Port, you can specify any ULONG_PTR value which you can use as a "key" value so you can sort out the various handles in the receiving threads. You can put anything into this value you want, and all transactions taking place on a particular handle will present this value when a queue entry for that handle is retrieved from the queue.
A thread which is handling the I/O request can be written very simply: it is a loop that does a very small number of things, then goes back and waits again. There is no need to do a complex WaitForMultipleObjects, perhaps with a timeout, to handle multiple concurrent I/O operations, or manage arrays of handles, or auxiliary arrays that correlate the handles to the context of the I/O operation. There is no need to manage the creation, release, and possible caching of Event objects. There is no reason to poll for completion, or deal with what happens to the initiating thread if the data is not available.
It is usually important to sort out the details of the actual transaction as well, and I describe that technique, of extending the OVERLAPPED structure, in a later section.
The greatest problem you typically end up with in dealing with the code is the potential concurrency with other threads. For example, if you need to update a disk file based on the completion, you have to synchronize access to the file so that no two threads are trying to write at the same time. But don't think of LockFileEx as the solution here! Instead, create a "logging thread" that logs information to a file, and make it the only thread that logs information to a file. Then simply enqueue requests to the logging thread from each of your handler threads, and trying to debug a complex synchronization problem is solved.
If you can reason about a problem and reduce it to its essentials, you don't need to write complex code. Very simple code suffices.
Code that is easy to reason about is easy to debug. You don't have to deal with a lot of complex timing issues; if you've reasoned about it correctly, it wasn't hard to write, so it won't be hard to debug!
When an I/O Completion Port is used, you can specify an explicit maximum concurrency value to the port. The suggested value is the number of processors available, or for large multiprocessor systems, the desired number of processors to be used for processing. You can also use 0 as a value, which means "no limit".
You then create a number of threads that all run using GetQueuedCompletionStatus to wait for items in the queue.
When an I/O operation completes, if there is a thread waiting, it will be allowed to proceed from the GetQueuedCompletionStatus, having removed the information from the queue.
If you have set a maximum concurrency limit, then no more than that many threads can be off processing the request. However, if one of these threads blocks, such as on some I/O operation performed in response to the request (example: logging something to a disk file; waiting for some synchronization object) then it is removed from the "current concurrency count", so other threads could now dequeue items from the I/O Completion Port. This means that you could create more threads than your concurrency limit, but no more than the concurrency limit number of threads can be off handling requests (if a blocked thread resumes, it does not suddenly stop a running thread; the concurrency limit is a heuristic to optimize performance).
The key is anything you want it to be. It is a UINT_PTR, so it is large enough to hold a pointer or a handle. However, there is at most one key per file connected to the I/O Completion Port. Most commonly I use the file handle as the key, although in some cases, I just use a nonzero value of my choice. Generally, you can pass the handle as part of the extended OVERLAPPED structure, so there is no need to pass it as the key.
I tend to use an INFINITE timeout for the GetQueuedCompletionStatus, which now introduces the question of how to shut the threads down gracefully? What I do is associate a nonzero key value with each file handle I associate with the I/O Completion Port. Sometimes, I just associate "1" with every actual handle, and sort the mess out by using the extended OVERLAPPED structure. This allows me to use the value "0" to indicate a thread-control message. Most commonly, it is simply the one-and-only thread control message, and it tells the thread to shut down.
#define THREAD_SHUTDOWN_REQUEST 0
To shut the threads down, I issue the following call. I issue as many of these as worker threads I have started for the I/O Completion Port.
PostQueuedCompletionStatus(port, 0, THREAD_SHUTDOWN_REQUEST, new OVERLAPPED);
The thread loop looks like this:
while(TRUE)
{ /* completion port loop */
DWORD bytesRead;
ULONG_PTR key;
PIOINFO info;
BOOL b = ::GetQueuedCompletionStatus(port, &bytesRead, &key, (LPOVERLAPPED *)&info, INFINTE);
if(b)
{ /* successful */
if(key == THREAD_SHUTDOWN_REQUEST)
{ /* shutdown */
delete info;
break;
} /* shutdown */
//... handle the information
} /* successful */
} /* completion port loop */
Whenever callback I/O or I/O Completion Ports are used, there is usually a need to correlate the actual I/O event with whatever it was intended to represent. For example, there is no way to determine, from the information delivered to either the callback function or the GetQueuedCompletionStatus, where the buffers are located.
There are two ways to deal with this, for C and C++. For C, the technique is to create a struct which has the OVERLAPPED structure as its first member
typedef struct {
OVERLAPPED ovl;
// put your information here
} IOINFO, *PIOINFO;
for example, in the "put your information here" you might put something like
DWORD bytesTransferred;
LPBYTE buffer;
which would make the buffer and length available. It might be used in the following fashion
At the initiating site
PIOINFO info;
info = new IOINFO;
info->ovl.hEvent = NULL;
info->buffer = new BYTE[ MY_BUFFER_SIZE ];
DWORD bytesRead;
BOOL b = ReadFile(handle, info->buffer, MY_BUFFER_SIZE, &bytesRead, &info->ovl);
if(!b)
{ /* failed */
DWORD err = GetLastError();
if(err != ERROR_IO_PENDING)
{ /* really failed */
...deal with it
} /* really failed */
} /* failed */
// if we get here, the operation succeeded.
Note that we don't do anything about the fact that the I/O succeeded immediately, because the completion is actually handled by the thread associated with the I/O Completion Port.
The I./O Completion port handler thread looks like this:
while(TRUE)
{ /* thread loop */
DWORD bytesRead;
ULONG_PTR key;
PIOINFO info;
BOOL b = GetQueuedCompletionStatus(port, &bytesRead, &key, (LPOVERLAPPED *)&info, INFINTE);
if(b)
{ /* successful */
//... handle the information
//...slightly different for C and C++
} /* successful */
else
{ /* failed */
// why did it fail?
if(info == NULL)
{ /* GetQueuedCompletionStatus failed */
DWORD err = GetLastError())
if(err == WAIT_TIMEOUT)
{ /* timed out */
// this case cannot happen if the time is INFINITE, but if the timeout
// were non-INFINITE, you would handle it here
continue;
} /* timed out */
else
{ /* genuine failure */
// this should not happen!
continue;
} /* genuine failure */
} /* GetQueuedCompletionStatus failed */
else
{ /* I/O operation failed */
DWORD err = GetLastError();
// ... report here that the I/O operation failed
// ... slightly different for C and C++
} /* I/O operation failed */
} /* thread loop */
The handlers for success would be something like
// successful I/O operation info->bytesTransferred = bytesRead; // ...do something with the buffer contents // ...perhaps pass this off to another thread to communicate to some other site
In C++, it is a bit easier, but there are some restrictions. For example, extending the OVERLAPPED structure is straightforward:
class IOINFO : public OVERLAPPED {
public:
DWORD bytesTransferred;
LPBYTE buffer;
};
but if you want to add a destructor, you must not exercise "best practice" and make it virtual. This is because you must not use any virtual methods, because they add the vtable (the virtual method dispatch table) as the first element of the structure, and this will be fatal to correct behavior.
class IOINFO : public OVERLAPPED {
public:
DWORD bytesTransferred;
LPBYTE buffer;
IOINFO(DWORD size) { hEvent = NULL; buffer = new BYTE[size]; }
/* must not be virtual */ ~IOINFO() {delete [ ] buffer; }
}
The I./O Completion port handler thread looks like the one for C, although I would use ::GetQueuedCompletionStatus and ::GetLastError as names.
If what I'm doing involves updating some GUI component, I will typically do a PostMessage call as part of the handling to update the GUI. This will also mean that lengthy computations like GUI update are not part of the thread execution, as they might well be if callback I/O were done. If I have to send a request back out on an Internet connection, I'll typically use the raw SOCKET data type, and pass the request off to yet another thread to handle the network transaction. Note that asynchronous network I/O using CAsyncSocket requires a "UI thread"; for the framework of how this can be handled, see my essay on UI Threads.
The notion of "asynchronous" is relative. For a device, such as a disk file, which has a bounded time for response, and no possibility of hanging, you may not need to use asynchronous I/O, except to keep the GUI from hanging. Or, you may wish to support the abort of a file transfer in the middle. But there is no need to use asynchronous I/O for this purpose. Simply spinning off a thread that has a synchronous ReadFile/WriteFile loop is sufficient. The "asynchronous" is with respect to the GUI thread, not the actual I/O transfer.
BOOL completed = FALSE;
while(running)
{ /* copy loop */
DWORD bytesRead;
if(!ReadFile(h, buffer, BUFFER_SIZE, &bytesRead, NULL))
{ /* error */
... deal with it
} /* error */
if(!running)
break;
if(bytesRead == 0)
{ /* complete */
completed = TRUE;
break;
} /* complete */
if(!WriteFile(h, buffer, bytesRead, &bytesWritten, NULL))
{ /* write error */
... deal with it
} /* write error */
} /* copy loop */
if(!completed)
{ /* failed to complete */
...
} /* failed to complete */
Disk I/O may or may not be asynchronous, even if you open the file in FILE_FLAG_OVERLAPPED mode. For all the details, consult Knowledge Base article 156932.
I/O will be forced to be synchronous under the following conditions:
 To
force truly asynchronous disk I/O, the file must be opened with
FILE_FLAG_NO_BUFFERING. This bypasses the cache mechanism. Note
that FILE_FLAG_SEQUENTIAL_SCAN and FILE_FLAG_RANDOM_ACCESS can
impact the asynchronous behavior as well. The problem with using
FILE_FLAG_NO_BUFFERING is that you can only access offsets which are a
multiple of the disk sector size, and only read blocks of data that are a
multiple of the disk sector size.. The GetDiskFreeSpace call will
return the bytes-per-sector as one of its output parameters. So using
asynchronous I/O imposes some limitations on doing random access that add a bit
of complexity to a program.
To
force truly asynchronous disk I/O, the file must be opened with
FILE_FLAG_NO_BUFFERING. This bypasses the cache mechanism. Note
that FILE_FLAG_SEQUENTIAL_SCAN and FILE_FLAG_RANDOM_ACCESS can
impact the asynchronous behavior as well. The problem with using
FILE_FLAG_NO_BUFFERING is that you can only access offsets which are a
multiple of the disk sector size, and only read blocks of data that are a
multiple of the disk sector size.. The GetDiskFreeSpace call will
return the bytes-per-sector as one of its output parameters. So using
asynchronous I/O imposes some limitations on doing random access that add a bit
of complexity to a program.
To demonstrate this, I created a little application called the Asynch Explorer. It can be downloaded from the Download option shown below.
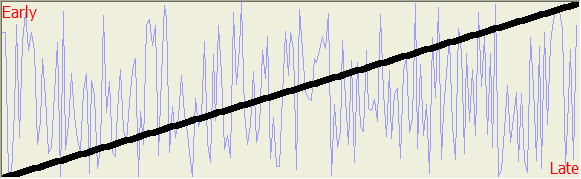
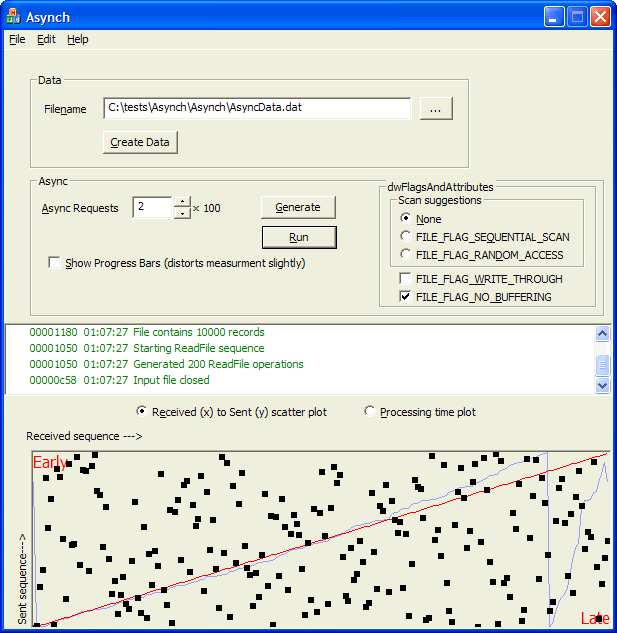 The
figure here shows a classic curve for asynchronous I/O. In this case, the
FILE_FLAG_NO_BUFFERING was selected. The scatter plot represents
the sequencing of the completion of the ReadFile operations. The
X-axis represents the order in which the operations were received. The
Y-axis represents the order in which the operation was issued. If the
operations were received in FIFO order (received in the same order they were
issued) then all the points would lie along the "Synchronous Line" shown in red.
If an operation was issued at time T36 but is received at time T24,
then it was received earlier than it was sent. It will appear in the upper
half of the graph, above the synchronous line, the section labeled "Early".
If an operation were issued at time T36 and is retrieved at time T48,
it has been delayed, and has arrived "Late". It will be in the lower half
of the graph, below the synchronous line.
The
figure here shows a classic curve for asynchronous I/O. In this case, the
FILE_FLAG_NO_BUFFERING was selected. The scatter plot represents
the sequencing of the completion of the ReadFile operations. The
X-axis represents the order in which the operations were received. The
Y-axis represents the order in which the operation was issued. If the
operations were received in FIFO order (received in the same order they were
issued) then all the points would lie along the "Synchronous Line" shown in red.
If an operation was issued at time T36 but is received at time T24,
then it was received earlier than it was sent. It will appear in the upper
half of the graph, above the synchronous line, the section labeled "Early".
If an operation were issued at time T36 and is retrieved at time T48,
it has been delayed, and has arrived "Late". It will be in the lower half
of the graph, below the synchronous line.
The lighter trace represents the seek address for the operation as received. Note there is a correlation in that most of the operations appear to be correlated with the seek distance, but not entirely. This could be due to anything from some type of disk caching (on the drive, for example), or scheduling, or disk fragmentation effects.
To use the program, the sequence of steps is shown below.
Use the Create Data button to create a data file. Something fairly large should be used for a sample file. This will provide not only a large amount of space to search, but also provide a chance to have the file badly fragmented, unless you've done a recent defragmentation.
If you have an existing data file you already want to experiment with, you can use the Browse [...] button to search for one. The file must have been created with the Create Data button, or conform to the requirements for the file format.
Select a number of ReadFile calls to issue The default is 1,000 (10×100), but you can select any range from 100 to 100,000 records in the file.
The options you select will be remembered from
execution to execution. I use my Registry Library
for this purpose.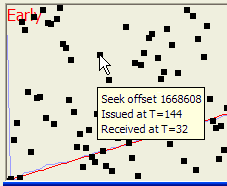
Given that you have a selected file, you can now run a sequence of tests on it. The first thing to do is to click the Generate button to select a random sequence of seek addresses. All subsequent Run operations will be based on this sequence of addresses, until you Generate another one.
Each Run operation will open the file using the selected options selected from the dwFlagsAndAttributes controls.
The Run button then issues a series of ReadFile requests, based on the selected count. The program starts up two threads, one to issue the ReadFile requests and one to receive them, using an I/O Completion Port to do the receipt.
There are two different displays that can be selected. In the first display, the Received/Sent display, the scatter plot shows the relative FIFOness of the I/O. In the second display, the Processing Time Plot, shows the amount of time spent on each I/O operation. In this plot, the X-axis is the sequence in which the ReadFile was issued, and the Y-axis is the delta-T between the time the ReadFile was issued and the I/O Completion Event was dequeued, using QueryPerformanceCounter to get the high-resolution timer. The time is converted from ticks to microseconds by using the QueryPerformanceFrequency call. This has not been corrected for a number of artifacts that could perturb the result. These include scheduler delays, clock skew of the CPU high-resolution clocks in a multiprocessor, and the like. However, the results are often rather interesting. The details of each point can be found by dragging the mouse over a point and seeing what information is displayed.
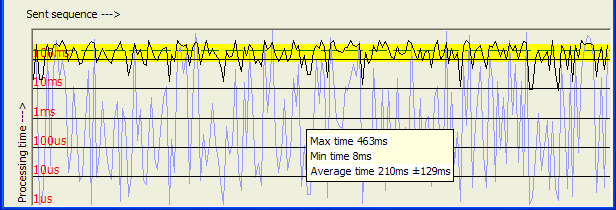 As far
as I can tell, there is caching going on, in spite of the
FILE_FLAG_NO_BUFFERING flag being set. Subsequent re-runs of the data
will go from incredibly long times, in the tens of milliseconds, to something
that converges on pure FIFO. I suspect either there is some internal
buffering going on in the kernel, or, more likely, the onboard cache of the disk
drive is coming into play. Note the disk address line is now sorted by
sent sequence, not received sequence, and consequently shows the randomness of
the selections. Compare this line to the line representing the addresses
in the first figure, where you can see that the addresses appear to be handled
in address order.
As far
as I can tell, there is caching going on, in spite of the
FILE_FLAG_NO_BUFFERING flag being set. Subsequent re-runs of the data
will go from incredibly long times, in the tens of milliseconds, to something
that converges on pure FIFO. I suspect either there is some internal
buffering going on in the kernel, or, more likely, the onboard cache of the disk
drive is coming into play. Note the disk address line is now sorted by
sent sequence, not received sequence, and consequently shows the randomness of
the selections. Compare this line to the line representing the addresses
in the first figure, where you can see that the addresses appear to be handled
in address order.
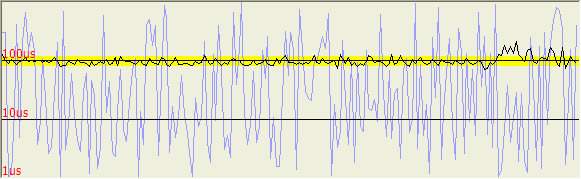
Note also that this graph is a logarithmic rather than linear graph. The bottom line shown here is 1µs and the top line is 100ms. If you move the mouse over the window, the little info window will pop up. This one shows that for this experiment, the max delay time was 463ms, and the minimum time was 8ms, so the average time was 210ms ±129ms, where 129ms is one standard deviation on each side. The mean time appears as a dashed line and the yellow rectangle shows the 1-sigma spread around the mean. Note that the "mean" is not in the center of this area because it is a logarithmic scale.
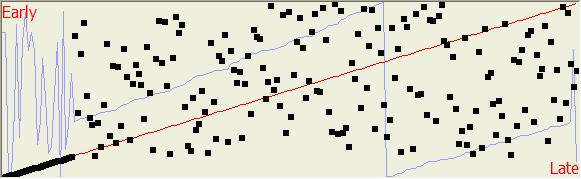 Note
that after some number of experiments, you may find something like the third
illustration here. In this figure, note that there is a FIFO order to the
first few requests, then it degenerates to fairly random.
Note
that after some number of experiments, you may find something like the third
illustration here. In this figure, note that there is a FIFO order to the
first few requests, then it degenerates to fairly random.
However, without the FILE_FLAG_NO_BUFFERING flag, the scatter plot is completely linear representing the fully synchronous I/O going on, in spite of the FILE_FLAG_OVERLAPPED selection. Also, the time plot now shows significantly lower times, from ReadFile to I/O Completion notification.
In the figure shown here, The max time was 154µs, the min time was 68µs, with a mean of 91µs±12µs. When the scatter plot for buffered I/O is displayed, it shows completely linear correlation. Note that the "seek line" in both displays is identical, because we see the seeks occurring in the order they were created.
The graphs without captions were saved directly to the clipboard using my window-to-clipboard library.
There are two kinds of files that can be saved from the program. One is an XML-formatted file which can be read by some post-processing analysis program. Another is a comma-separated list which can be loaded into programs such as Excel. These are handled by the File menu. The comma-separated list format is shown below
Received, Sent, Time, Record
0, 0, 3.992, 8436224
1, 2, 3.864, 2560
2, 3, 12.186, 214528
3, 33, 19.689, 503296
4, 95, 20.853, 648704
5, 96, 20.964, 655872
6, 72, 30.108, 857600
7, 65, 33.116, 943616
The Time column is expressed in milliseconds, to three decimal places (microseconds).
The XML output appears as
<?XML version 1.0"?>
<PLOT:Plot>
<PLOT:Parameters>
</PLOT:Parameters>
<PLOT:Data>
<PLOT:Seek>
<PLOT:Address i "0" offset "8436224"/>
<PLOT:Address i "1" offset " 2560"/>
<PLOT:Address i "2" offset " 32256"/>
...
<PLOT:Address i "97" offset "4884992"/>
<PLOT:Address i "98" offset "4902400"/>
<PLOT:Address i "99" offset "4946432"/>
</PLOT:Seek>
<PLOT:Sequence
<PLOT:Seq i "0" src "0"/>
<PLOT:Seq i "1" src "2"/>
<PLOT:Seq i "2" src "47"/>
<PLOT:Seq i "3" src "66"/>
...
<PLOT:Seq i "97" src "136"/>
<PLOT:Seq i "98" src "18"/>
<PLOT:Seq i "99" src "132"/>
</PLOT:Sequence
<PLOT:Times
<PLOT:Time received "0" sent "0" time " 0.027629" record "8436224"
<PLOT:Time received "1" sent "2" time " 0.027523" record "2560"
<PLOT:Time received "2" sent "47" time " 0.024296" record "32256"
<PLOT:Time received "3" sent "66" time " 0.022916" record "54784"
...
<PLOT:Time received "96" sent "32" time " 0.203651" record "4752896"
<PLOT:Time received "97" sent "136" time " 0.198518" record "4884992"
<PLOT:Time received "98" sent "18" time " 0.209193" record "4902400"
<PLOT:Time received "99" sent "132" time " 0.200750" record "4946432"
</PLOT:Times
</PLOT:Data>
</PLOT:Plot>
29-May-06 Fixed a bug in CreateEvent, the earlier version had a second argument of FALSE and it should have had a second argument of TRUE (Thank you, Peter, for pointing that out!)
![]()
The views expressed in these essays are those of the author, and in no way represent, nor are they endorsed by, Microsoft.